Python爬虫-Selenium框架使用 | 字数总计: 2.6k | 阅读时长: 11分钟 | 阅读量:
Selenium4+xpath 1.简介 Selenium是当前广泛使用的开源自动化测试框架之一,它提供了丰富的工具和库,用于自动化测试Web应用程序。
Selenium的主要功能是模拟用户与Web应用程序的交互,并能够自动化执行各种操作,如点击按钮、填写表单、验证页面元素等。通过这种方式,测试人员可以快速有效地执行大规模的测试,并验证应用程序在各种情况下的可靠性和稳定性。
在实际渗透时,我们有时需要模拟人类对网站进行访问,或对网站进行某些自动化行为,我们可以借助Selenium框架实现。
2.xpath 2.1xpath简介 XPath使用一种类似于目录结构的路径表达式,该表达式可以从根节点开始或当前节点开始,通过层级关系和条件筛选来定位所需的节点。XPath支持广泛的节点选择符号,如标签名、属性值、位置、逻辑运算符等,从而实现灵活的节点选择和过滤。
2.2安装模块 2.3xpath使用 2.3.1.etree etree 把 html源码变成对象
import requestsfrom lxml import etreedef main (): url = "http://www.4399dmw.com/donghua/" headers = { "User-agent" :"User-agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url=url,headers=headers) html_doc = resp.content.decode("utf-8" ) html = etree.HTML(html_doc) print (html.xpath("xpath语法" )) pass
2.3.2xpath语法 xpath语法中[1]就是第一个
基础用法
//a 查询当前HTML页面所有的a标签 //a/@href 当前html页面中所有a标签中的href的属性内容 //a/text() 所有a标签中的文本内容
属性处理
//img/@src 拿到所有img标签中src的内容 //a/img/@src 拿到所有a标签中的img标签里的src的内容 //img[@alt='某个值']/@src 选择img标签中alt是某个值的标签并且提取src值
class标签处理
//a[@class='u-card'][1]/img 选到所有的a标签下的class的值为u-card中的第1个的img标签 //div[@class='lst-item'][3]/a[4]/img 选取页面中所有div且class等于lst-item选择其中第三个,在此之下选择第四个a标签下的img标签 //div[@class='lst-item'][1]/a[last()]/img 这里的a标签是选择最后一个
p标签
//p[text='超变武兽第二季']查找所有p标签中,文字内容是xxx的 //p[contains(text(),'蜡笔')] 查找所有p标签中,包含某些文字的 //p[@*] 页面中所有p标签凡是带有属性的都选出来
div标签
//div[@class='lst-item'][2]/* 将所有div标签class属性等于lst-item中的第二个中的所有内容 //div[@class='m-lst']/div[position()=4] 选择页面中所有class是m-ls的div中的第四个div
2.3.3实战 import requestsfrom lxml import etreedef main (): url = "http://www.4399dmw.com/search/dh-1-0-0-0-0-0-0/" headers = { "User-agent" :"User-agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url=url,headers=headers) html_doc = resp.content.decode("utf-8" ) html = etree.HTML(html_doc) donghuatitle = html.xpath("//div[@class='u-ct']/p[@class='u-tt']/text()" ) donghuapic = html.xpath("//div[@class='lst']/a/img/@data-src" ) print (donghuatitle) print (donghuapic) pass
把每一页都爬下来,自动寻找下一页
import requestsfrom lxml import etreedef pachong (url ): url = url headers = { "User-agent" :"User-agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url=url,headers=headers) html_doc = resp.content.decode("utf-8" ) html = etree.HTML(html_doc) donghuatitle = html.xpath("//div[@class='u-ct']/p[@class='u-tt']/text()" ) donghuapic = html.xpath("//div[@class='lst']/a/img/@data-src" ) print (donghuatitle) print (donghuapic) pass def find_next_page (url ): url = url headers = { "User-agent" :"User-agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url=url,headers=headers) html_doc = resp.content.decode("utf-8" ) html = etree.HTML(html_doc) next_page = html.xpath("//a[contains(text(),'下一页')]/@href" ) really_next_page = "http://www.4399.dmw.com" +nextpage[0 ] return real_next_page def main (): url = "http://www.4399dmw.com/search/dh-1-0-0-0-0-1-0/" while True : try : print ("开始爬行的url:" +url) pachong(url) url = find_next_page(url) except : break print ("最后一页也爬行完了" ) pass
在浏览器中中可下载xpath插件,方便写xpath语法匹配内容,
这里推荐
https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl?hl=zh-CN
3.selenium 3.1简介 Selenium是一款强大的开源自动化测试工具,用于模拟和控制浏览器行为,实现对Web应用程序的自动化测试。它支持多种编程语言和浏览器,提供了丰富的功能和灵活的API,是开发人员和测试人员首选的自动化测试解决方案。
3.2安装 1.selenium模块
手动下载chromedriver:
https://vikyd.github.io/download-chromium-history-version/#/
注意:需要下载chrome对应版本的驱动使用
自动安装:
pip install webdriver-manager pip install packaging
之后建立一文件
from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager driver = webdriver.Chrome(ChromeDriverManager().install()) driver.get("https://www.baidu.com/") driver.quit()
进度条满后自动则安装成功
3.3使用 1.打开网页
from selenium import webdriverimport timedriver = webdriver.Chrome() driver.get("https://www.baidu.com/" ) time.sleep(5 ) driver.quit()
2.按键包
from selenium.webdriver.common.keys import Keys driver.find_element("id" , "kw" ).send_keys("this s a test" ) driver.find_element("id" , "kw" ).send_keys(Keys.CONTROL,'a' ) driver.find_element("id" , "kw" ).send_keys(Keys.ENTER)
3.配置浏览器启动使用Option类
from selenium.webdriver.chrome.options import Optionsoptions = Options() options.add_argument('--window-size=1366,768' ) driver = webdriver.Chrome(options=options)
4.设置启动型号
mobileEmulation = {'deviceName' : 'iPhone 6/7/8' } mobileEmulation = { "deviceMetrics" :{ "width" :350 , "height" :200 , "pixelRatio" :3.0 , "touch" :False } } options.add_experimental_option('mobileEmulation' , mobileEmulation)
5.模拟点击
手机下操作鼠标!!有时候页面存在覆盖层,需要点击两次
这里像素点的获取推荐使用google插件Page Ruler Smart
from selenium.webdriver.common.action_chains import ActionChainsaction = ActionChains(driver).move_by_offset(70 ,120 ).click() action.perform() ActionChains(driver).move_by_offset(-70 ,-120 ).perform()
6.模拟悬停
获取登录位置示例
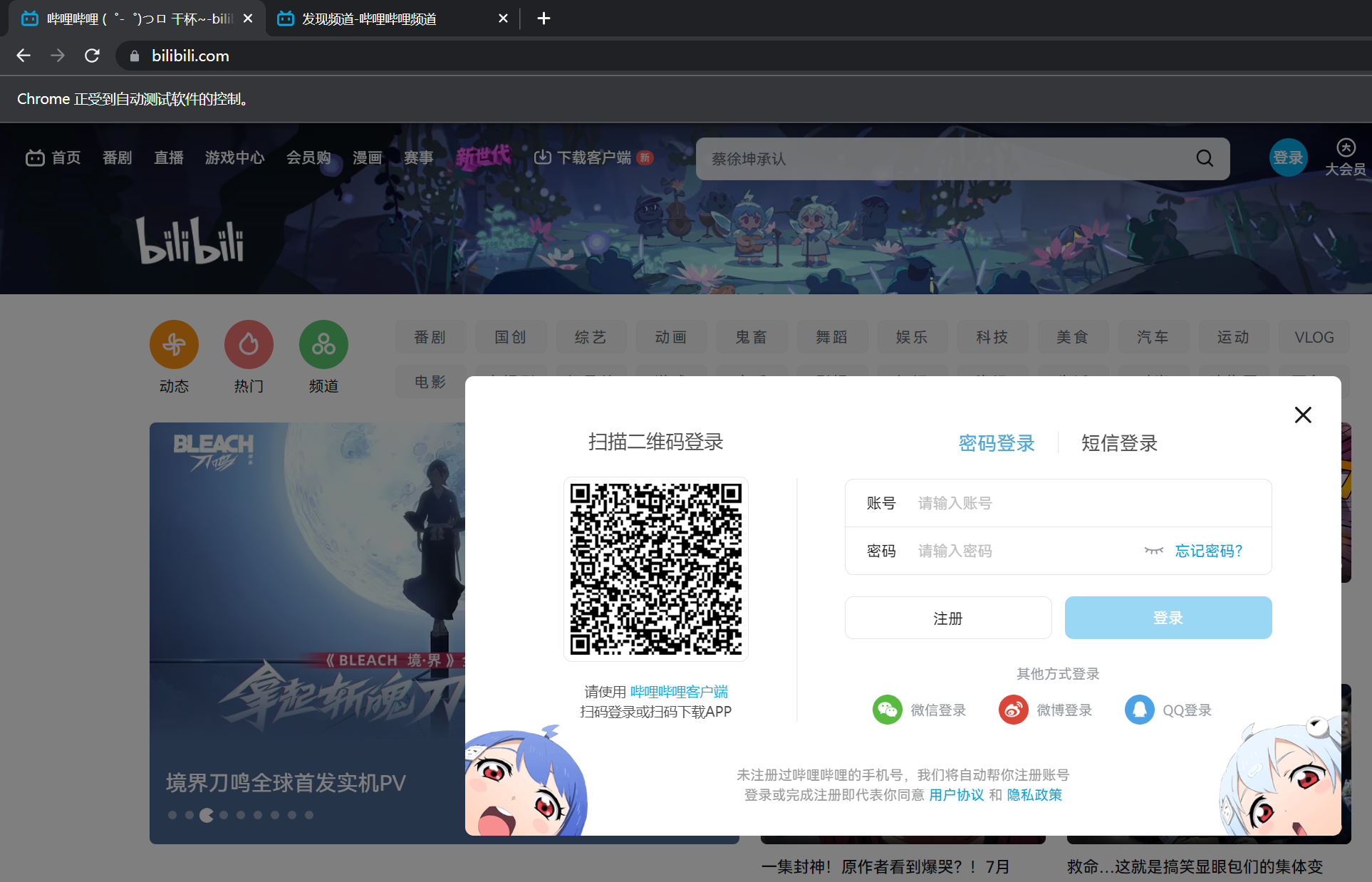
from selenium.webdriver.common.action_chains import ActionChainsfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome(options=options) driver.get("https://www.bilibili.com/" ) denglu = driver.find_element(By.XPATH,"//div[@class='header-login-entry']" ) ActionChains(driver).move_to_element(denglu).click().perform()
点击可以一次执行多个
driver = webdriver.Chrome(options=options) driver.get("https://www.bilibili.com/" ) pingdao = driver.find_element(By.XPATH,"//div[@class='icon-bg icon-bg__channel']" ) denglu = driver.find_element(By.XPATH,"//div[@class='header-login-entry']" ) action = ActionChains(driver) action.click(pingdao) time.sleep(2 ) action.click(denglu) action.perform() time.sleep(5 ) driver.quit()
测试结果:先点击频道,后点击登录
3.4模拟人类操作 1.手机处理拖拽操作
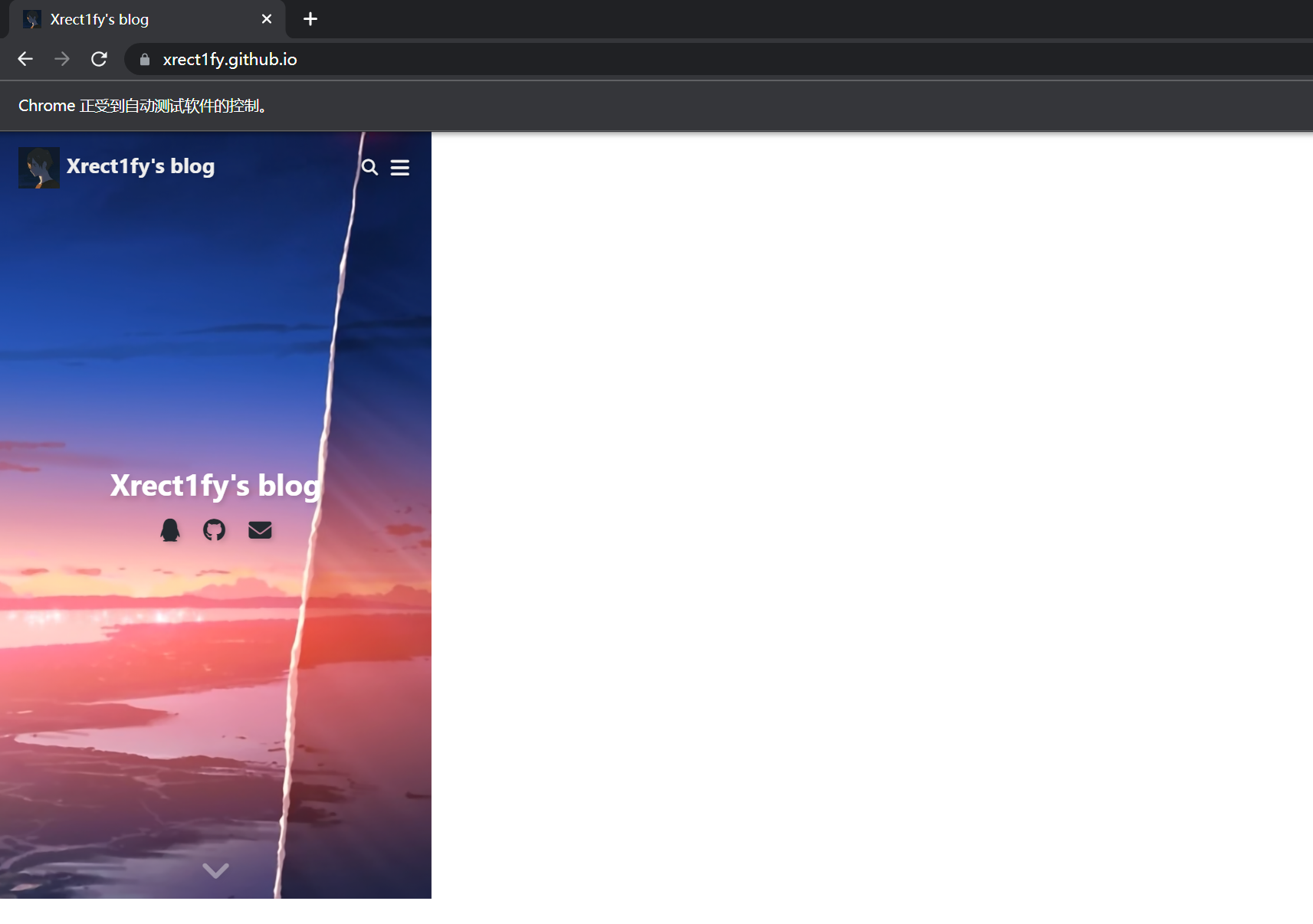
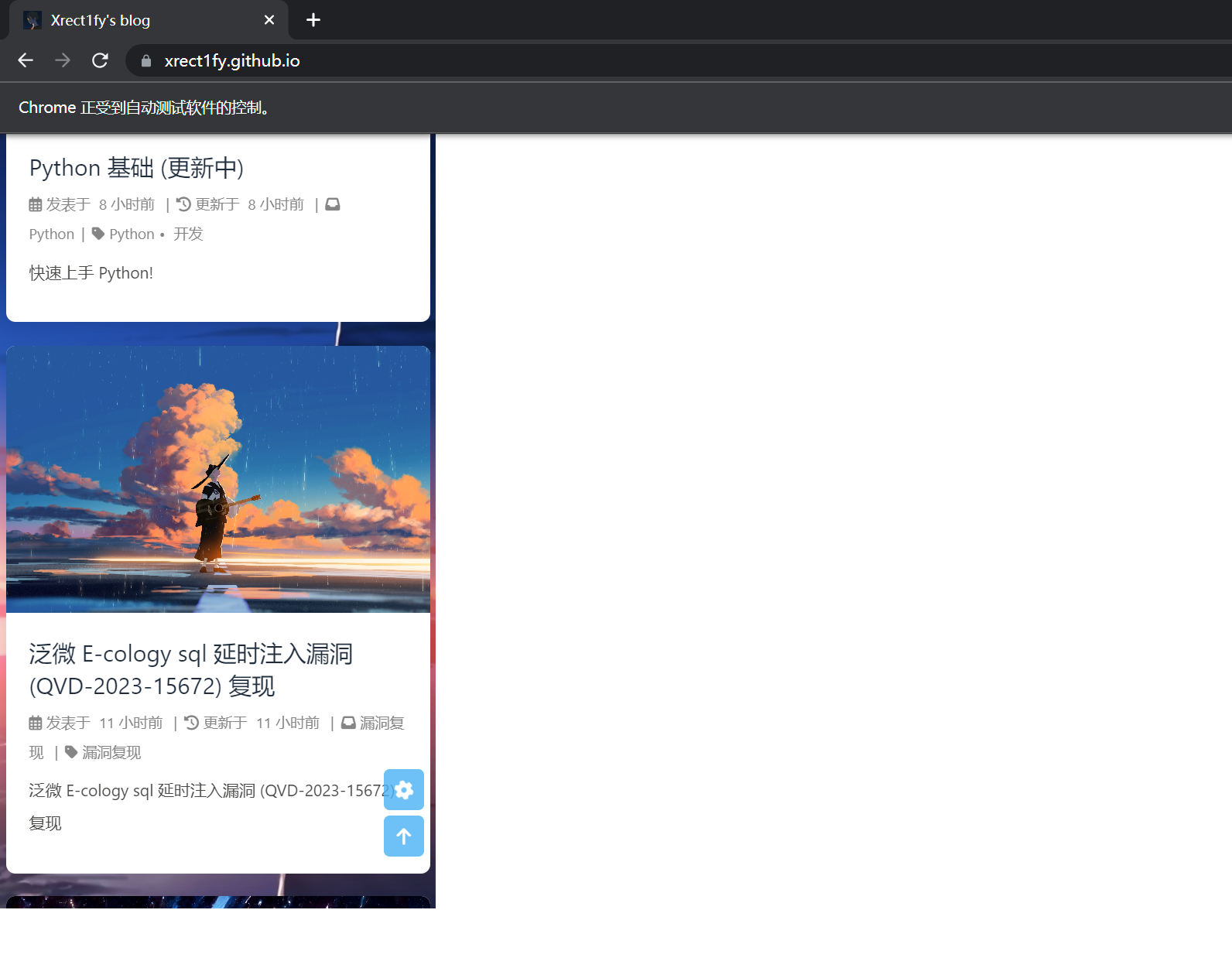
driver = webdriver.Chrome(options=options) driver.get("https://xrect1fy.github.io/" ) first_tar = driver.find_element(By.XPATH,"//a[@title='Python基础(更新中)'and@class='article-title']" ) second_tar = driver.find_element(By.XPATH,"//h1" ) action = ActionChains(driver) action.drag_and_drop(first_tar,second_tar).perform()
拖拽操作需要使用xpath或者其他方法找到起始位置和终末位置
first_tar是初始位置,second_tar是终末位置
初始:
终末:
2.鼠标点击像素的操作
ActionChains(driver).move_by_offset(200 ,300 ).click().perform() ActionChains(driver).move_by_offset(-200 ,300 )
3.点击写入只能一个一个字按
ActionChains(driver).move_by_offset(500 ,95 ).click().key_down("a" ).perform() ActionChains(driver).move_by_offset(-500 ,-95 ).perform()
鼠标操作
click()点击鼠标左键 click and hold() 点击鼠标左键不放 context_click() 点击鼠标右键不放 double_click() 双击鼠标左键 drag_and_drop() 鼠标拖拽 drag_and_drop_by_offset()鼠标拖拽到哪个坐标然后松开 key_down("a") 按下一个键 key_up("a") 抬起一个键 move_to_element(ele) 移动鼠标到某个元素的位置 move_to_element_with_offset(ele,100,0) 移动到某个元素的相对多少距离
根据像素拖拽
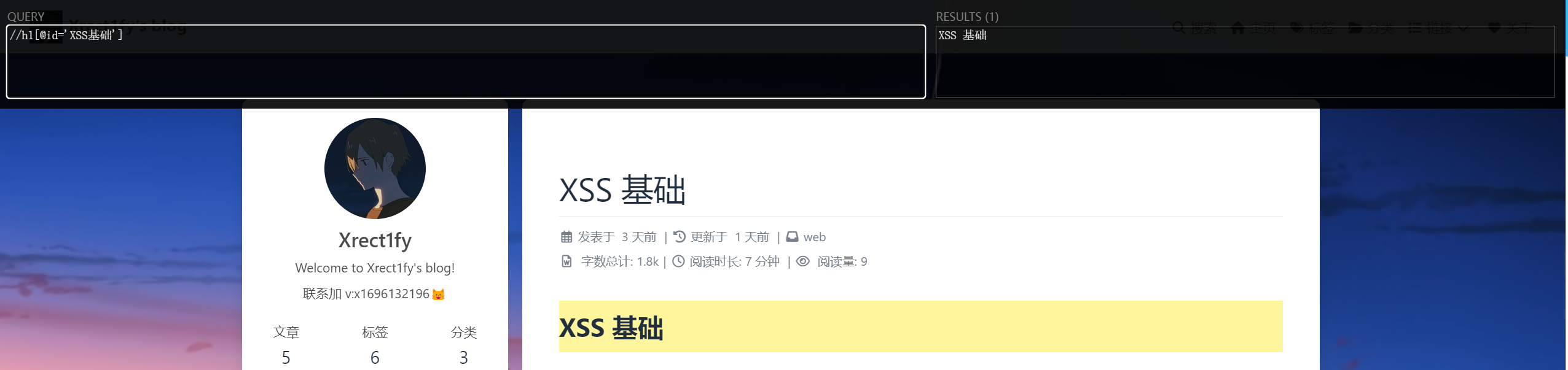
action = ActionChains(driver) first_tar = driver.find_element(By.XPATH,"//a[@title='XSS基础'and@class='article-title']" ) ActionChains(driver).drag_and_drop_by_offset(first_tar,0 ,10 ).perform()
4.处理下拉框
from selenium.webdriver.support.ui import Selectele = driver.find_element(By.XPATH,"//select[@class='year']" ) select1 = Select(ele) result = select1.select_by_value("动漫专区" )
5.新建选项卡
js = 'window.open("http://www.baidu.com")' driver.execute_script(js)
6.窗口切换
print (driver.current_url)driver.switch_to.window(driver.window_handles[1 ]) driver.switch_to.window(driver.window_handles[0 ])
7.关于iframe的处理
论坛
寻找到iframe的位置,聚焦转换到iframe上
find_div = driver.find_element(定位的元素) driver.switch_to.frame(find_div)
释放iframe,回到主页上!!
driver.switch_to.default_content()
8.处理弹窗
driver.switch_to.alert.accept()
4.参考文章 https://blog.csdn.net/wangqiang_cyou/article/details/128900832
https://blog.csdn.net/u013454322/article/details/128399381
selenium中的find_element方法