
信息收集学习与总结
1.信息收集(更新中)
1.1信息收集概述
1.1.1信息收集的基本要求
1.全面:
对目标所有的业务和非业务存在点进行全面的信息收集。
2.准确:
对收集到的信息尤其是重要信息要再三确认其信息的准确性。
3.失效:
注意信息产生时间和手机时间,是否具有时间差,时间差能否接受。
4.清晰:
对于收集到的信息要做到逻辑清晰,能清楚分辨出各个收集到的信息之间的逻辑关系和资产之间的相对位置。
5.拓步:
以信息起点由点到面。
1.1.2.信息搜集注意点
信息搜集底层逻辑: 通过各种渠道对已公开或未公开的信息进行搜集,尽可能搜集薄弱点。
注意事项:
1.降低被发现度,提高隐蔽性。
2.细心,耐心。
1.1.3收集目标
服务器ip
域名
操作系统
web容器 tomcat
端口
协议 http https
cdn 多地(国外)ping 查历史域名解析记录https://www.ip138.com/ 主站 流量⼤ 有cdn ⼦域名的站 流量⼩,没有cdn https 证书
⽤的什么语⾔ login.php index.jsp index.asp thinkphp
框架 tp cms
数据库 不是绝对: php——>mysql 开发难度低 中⼩公司 mysql免费 jsp——>oracle/mysql oracle 收费⽽且很贵 流量⼤的⼤型公司 asp——>sqlserver 微软⾃家的 (sqlserver堆叠注入+xpcmdshell)
负载均衡
waf
代码泄露:扫目录扫到备份文件
微信⼩程序
信任域名
界面上的js:看调用路径,有的不是调用的本地,调用的其他域名可能也是资产
接口
1.1.4信息收集分类
信息搜集主要分为两类:
1.被动信息搜集
2.主动信息搜集
1.2.信息收集流程
1.3.信息收集工具编写示例
1.子域名爆破
import requests |
2.fofa查询
# -*- coding: utf-8 -*- |
2.被动信息收集
2.1基本流程
- 第三⽅的信息收集机构或平台已经收集到⽬标的信息
- 第三⽅的信息收集机构或平台将信息存储在某处
- 攻击者从存储信息的地⽅查询信息
- 攻击者得到相应信息
2.2被动信息收集优缺点
1.优点:
1.隐蔽性高,不容易被发现
2.收集的信息量和覆盖面比较大
2.缺点
1.收集到的信息准确性与时效性不高
2.无法收集到敏感或未公开信息
应用场景:通过被动信息收集获取目标基本要素,根据信息要素判断目标特点与薄弱点
2.3 常见手段
1.Google语法
https://www.google.com
常用google语法:
site: 指定站点的内容(域名) |
Google语法查询对应漏洞database
https://www.exploit-db.com/google-hacking-database
2.网络空间搜索引擎语法及基本使用
常用推荐
fofa: https://fofa.info/ |
fofa为例
fofa常用:
title="abc" 标题中存在abc的站点 |
高级搜索
使用 () && || != |
推荐使用工具 fofa_view
项目地址:https://github.com/wgpsec/fofa_viewer
配置相关信息后即可使用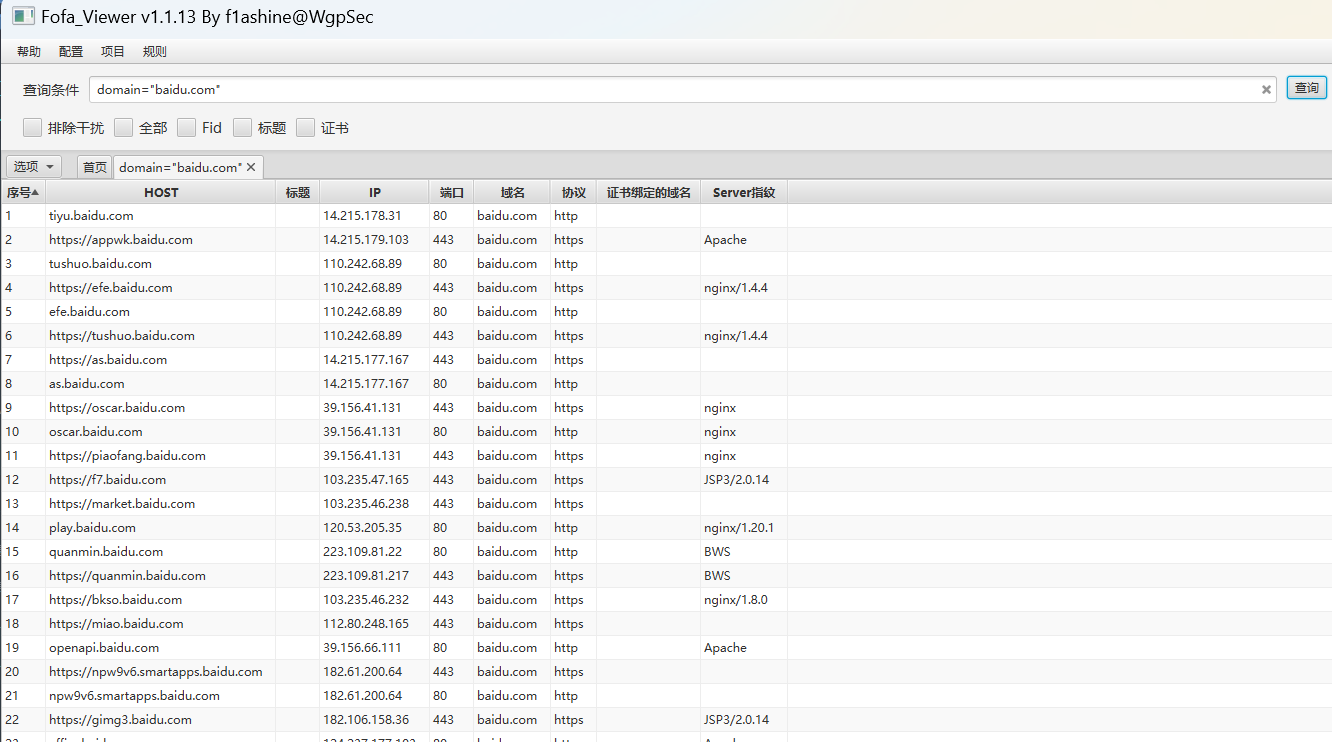
3.企业信息收集
国内:
天眼查https://www.tianyancha.com/
爱企查https://aiqicha.baidu.com/
小蓝本https://www.xiaolanben.com/
企查查https://www.qcc.com/
启信宝https://www.qixin.com/
国外
OpenCorporateshttps://opencorporates.com/
Wayback Machinehttp://web.archive.org/
零零信安:https://0.zone/
3.主动信息收集
3.1.主动信息收集的基本结构
基本流程:
- 由攻击者主动发起⾏为或请求
- ⽬标受到⾏为或请求影响并发出反馈
- 攻击者获得反馈并判断特征
3.2.主动信息收集的特点
主动信息收集的优缺点:
优点:
1.信息的针对性强
2.信息的准确度和时效性⾼
3.能收集到未公开的敏感信息(robots.txt,.rar)
缺点:
1.容易暴露,被发现的⻛险⾼(请求敏感内容,短时间同一ip访问次数大于某个值)
2.收集的信息量和覆盖⾯⽐较少
主动信息收集的应⽤场景:
主动信息通常在被动信息收集后分析出重要攻击面或敏感点再去针对性去做主动信息收集,在主动信息收集的时候通常持续时间比较长,而且会通过各种不同的方式与目标交互,实战中最常用的手段是模拟或伪装在正常业务流程与目标交互。
3.3.主动信息收集手段
域名
1.搜索引擎
| www.google.com | |
|---|---|
| Bing | www.Bing.com |
| Baidu | www.baidu.com |
2.网站备案
| ICP备案-站长之家 | http://icp.chinaz.com/ |
|---|---|
| ICP/IP/域名备案管理 | https://beian.miit.gov.cn/ |
| ICP备案信息查询 | https://www.icplist.com/ |
3.ip反查
| 微步在线 | https://x.threatbook.cn |
|---|---|
| Ip138反查 | https://site.ip138.com |
| 爱站网 | https://dns.aizhan.com |
| 站长之家 | https://stool.chinaz.com/same |
| RapidDNS Sameip | https://rapiddns.io/sameip |
4.AppinfoScanner
项目地址: https://github.com/kelvinBen/AppInfoScanner
支持对andriod,ios,web文件进行扫描 |
子域名
1.oneforall
config目录下有api.py用于配置api,配置的越全,搜集到的信息越全
项目仓库:https://github.com/shmilylty/OneForAll
根据文档安装 |
python oneforall.py --target example.com run |
扫描出的结果会放在results目录下的csv文件中
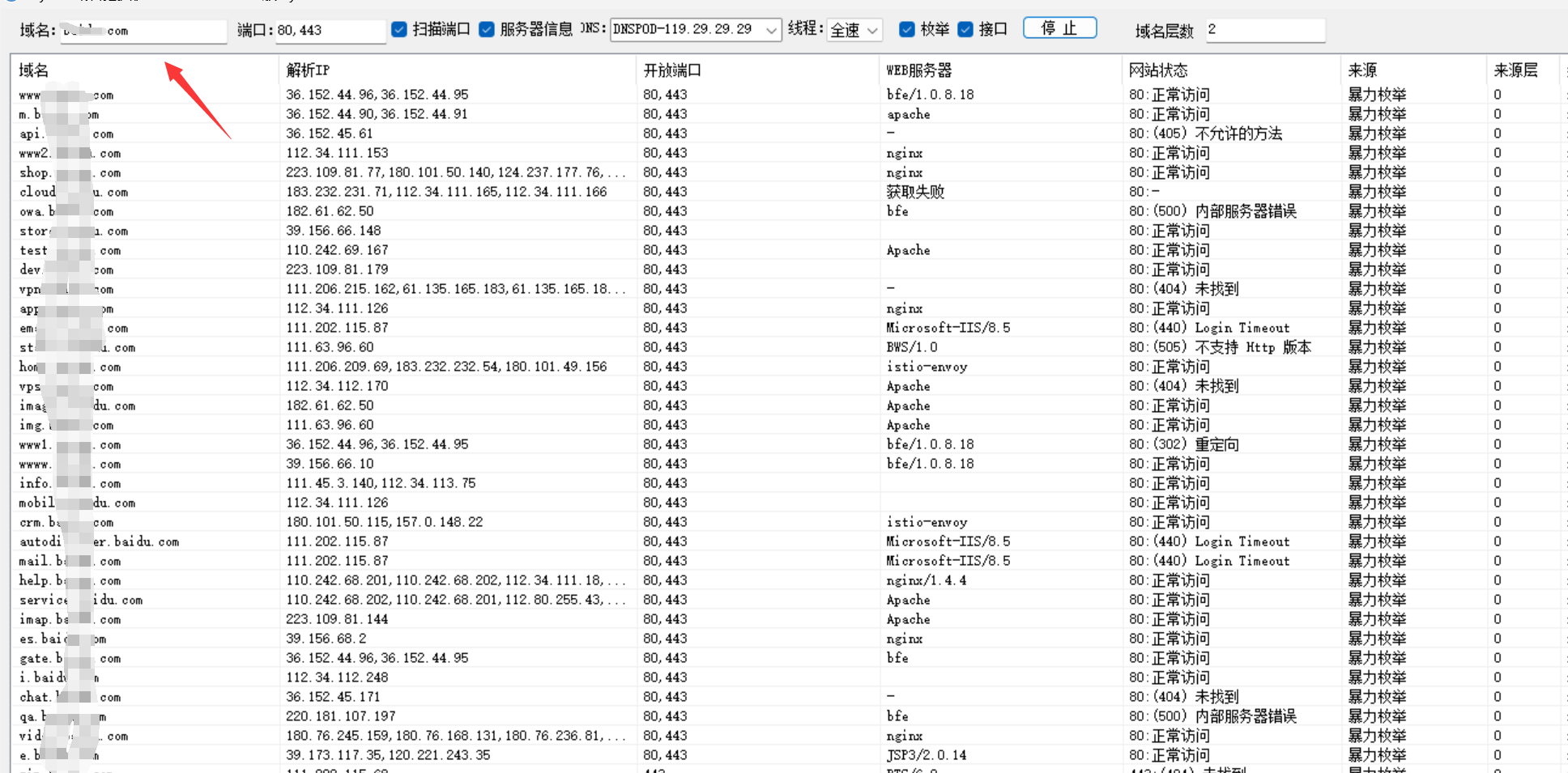
2.layer子域名挖掘机
双击layer.exe运行 |
3.jsfind
爬取指定目标中的链接等内容,从而进一步爬取子域名和URL信息
项目地址:https://github.com/Threezh1/JSFinder
简单爬取 |

4.subDomainsBrute
项目地址:https://github.com/lijiejie/subDomainsBrute
结果是子域名和对应ip
5.google语法
site:”baidu.com”
6.ksubdomain
Go编写,速度快
项目地址:https://github.com/knownsec/ksubdomain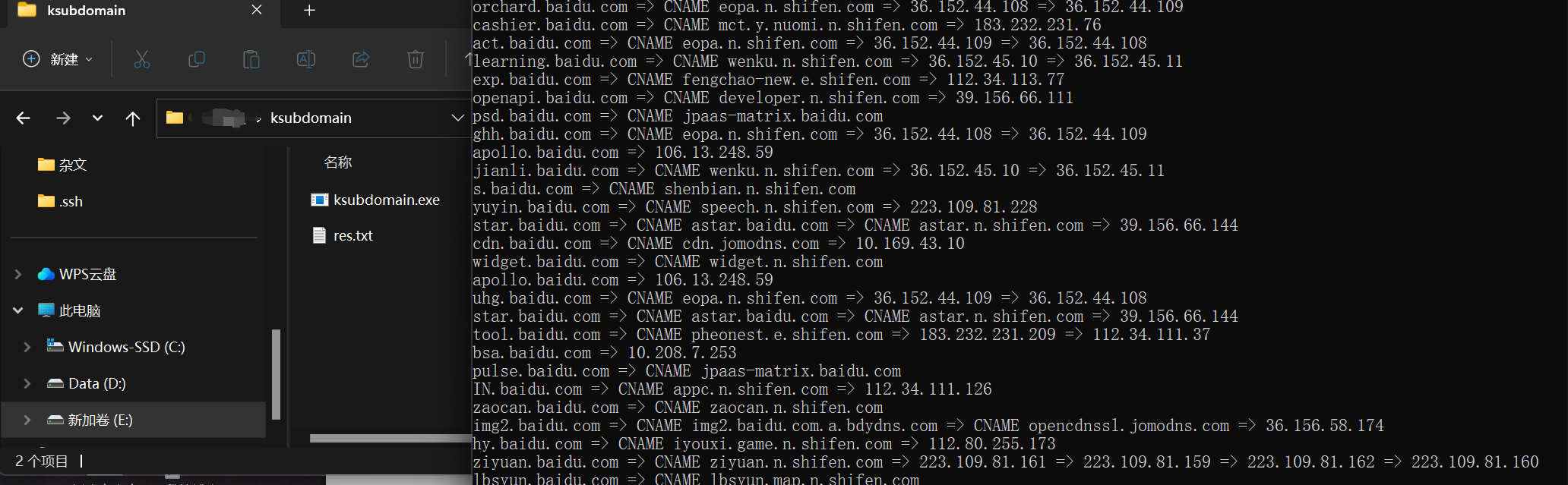
7.fofa查询
domain=”baidu.com”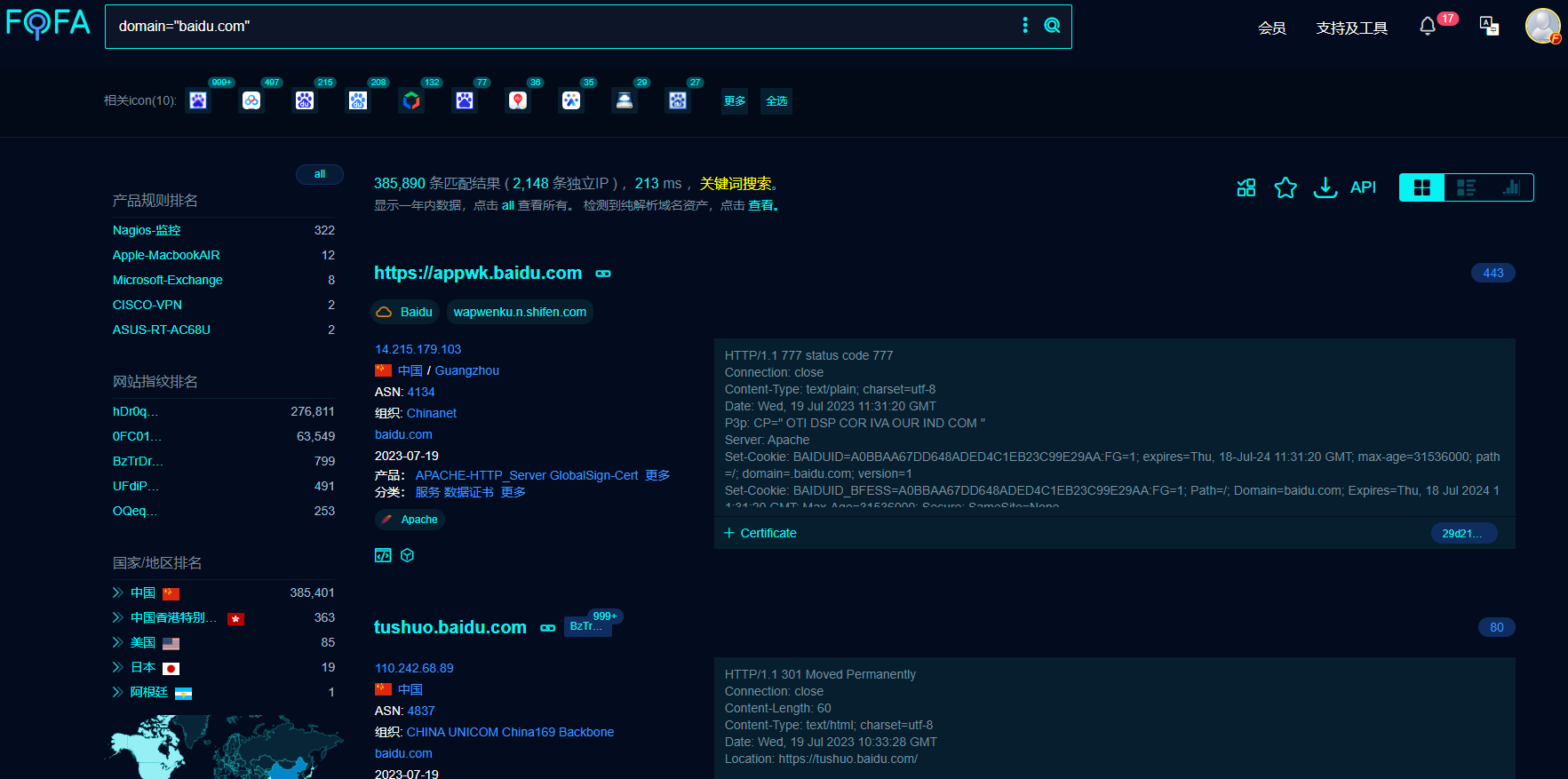
8.威胁情报网站
例如:微步在线-子域名选项
https://x.threatbook.cn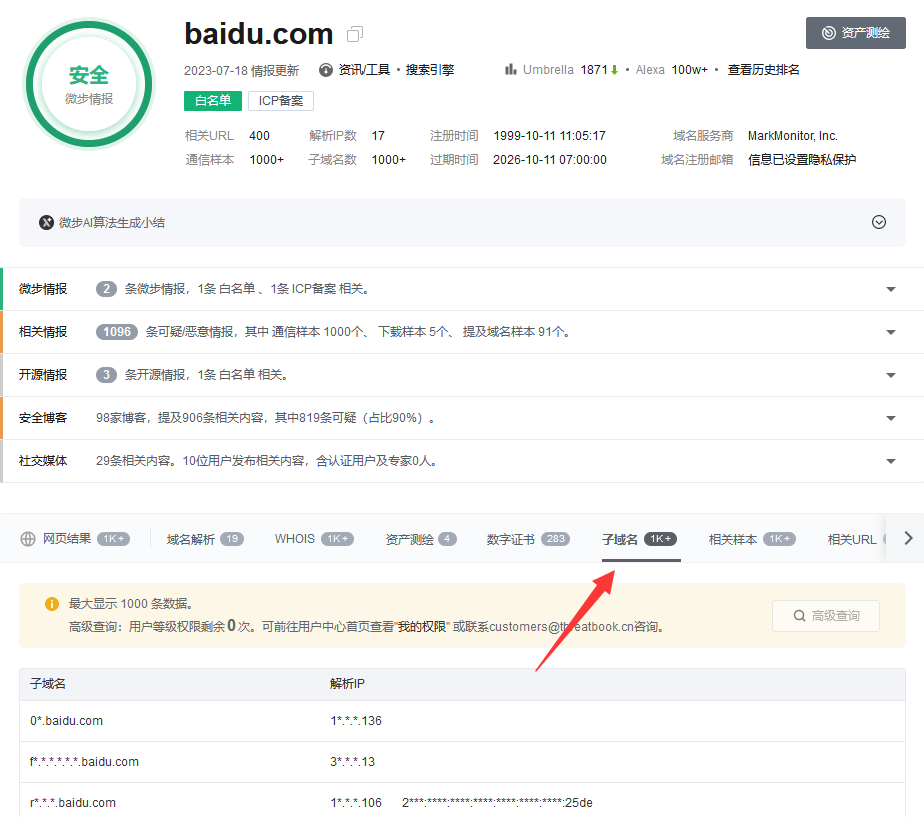
站长之家:https://tool.chinaz.com/subdomain/
端口扫描
1.masscan
项目地址:https://github.com/robertdavidgraham/masscan
单端口:masscan [ip] -p80 |

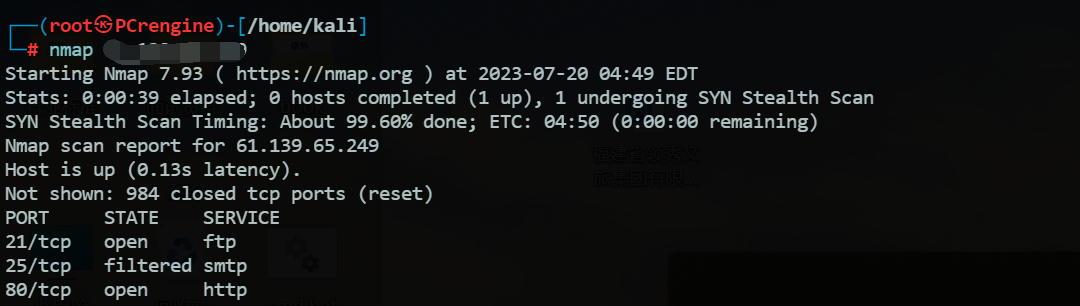
2.nmap
官网地址:https://nmap.org/
默认端口扫描:nmap [ip] |
3.goby
官网地址:https://gobies.org/
完成相关设定后直接扫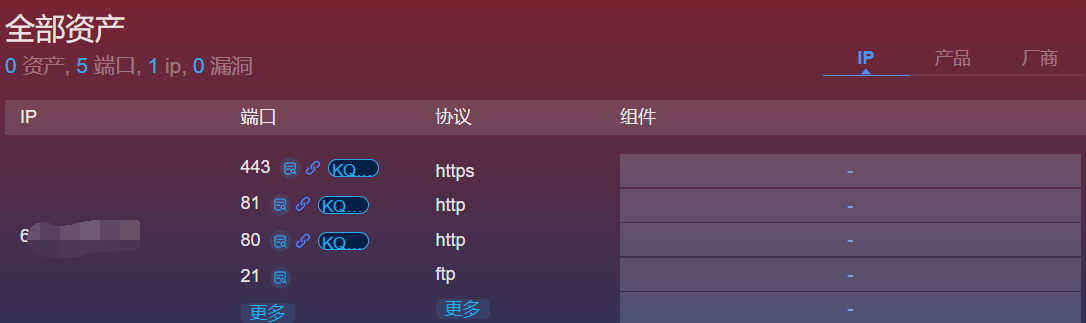
指纹识别
1.Wappalyzer
谷歌应用商店链接:https://chrome.google.com/webstore/detail/wappalyzer-technology-pro/gppongmhjkpfnbhagpmjfkannfbllamg?hl=zh-CN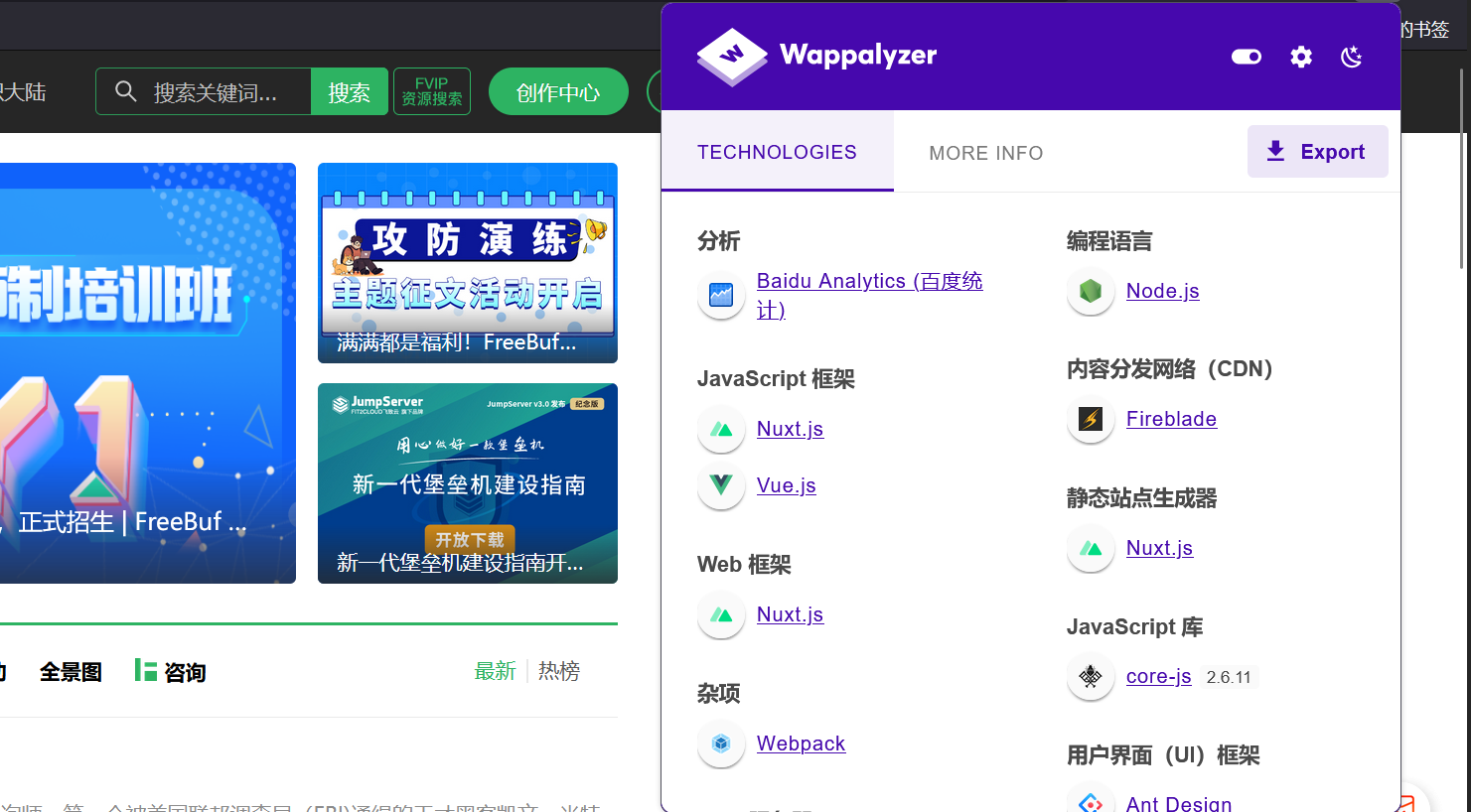
2.Ehole
可查指纹,可查C段权重 |
项目地址:https://github.com/EdgeSecurityTeam/EHole
3.Goby
下载地址:https://gobies.org/
4.whatweb
可以搜集网站的一些文字信息 |
项目地址:https://github.com/urbanadventurer/WhatWeb
5.潮汐指纹
http://finger.tidesec.com/
C段扫描
1.Ehole
项目地址:https://github.com/EdgeSecurityTeam/EHole
扫描后自动列出重点资产 |
2.Eeyes
项目地址:https://github.com/EdgeSecurityTeam/Eeyes
筛选真实IP并整理C段 |
3.fscan
项目地址:https://github.com/shadow1ng/fscan
网综合扫描工具,方便一键自动化、全方位漏扫扫描 |
4.ServerScan
项目地址:https://github.com/Adminisme/ServerScan
使用Golang开发且适用于攻防演习内网横向信息收集的高并发网络扫描、服务探测工具 |
CDN绕过
CDN
通过不同地理位置的缓存来加快访问速度,所以我们有可能访问的⽹⻚不是真实ip提供的⽹⻚
挂了CDN的服务器解析到的是cdnip并不是真实的目标ip
1.CDN价格昂贵,
旁站,子域名,c段可能没有CDN
2.DNS历史解析
CDN基于解析,所以查看较早的CDN解析记录解析到真正主机
查询网站
https://x.threatbook.cn
https://webiplookup.com
https://viewdns.info/iphistory
https://toolbar.netcraft.com/site_report
3.多地ping/国外ping
可能国内采用cdn
https://ping.aizhan.com
https://ping.chinaz.com
4.证书查询
域名的证书可能存在真实ip信息,如果目标站点配有https证书,我们可以查到所有相同证书的站点
https://search.censys.io
https://crt.sh
5.邮箱服务器
cdn不支持邮箱
邮件查看注册原文(信头),里面的邮箱服务器ip可能是真实ip
实战中让目标邮箱服务器向自己的伪造邮箱发送邮件,查看邮箱服务器ip
6.边缘业务的子域名
例如app,小程序子域名指向的ip
7.fofa查找网站标题查找
title=“”
得到站点ip,判断ip是否为主站
8.ajax应用架构
应用架构:
前后端不分离,bp返回包为html源码
前后端分离,返回包一般直接返回数据,通常是json数据
ajax请求不规范,以ip的形式进行调用
前端ajax去调用后台的api,他会访问后台的ip,此ip大概率为真实ip
目录扫描
1.dirsearch
项目地址:https://github.com/maurosoria/dirsearch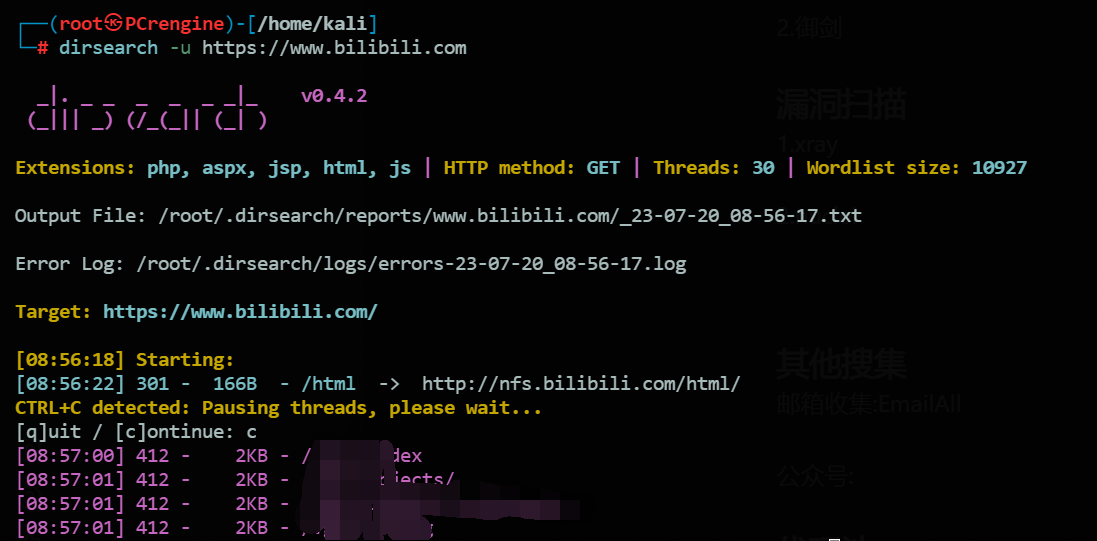
2.御剑扫描
漏洞扫描
1.xray
项目地址:https://github.com/chaitin/xray
xray文档:https://docs.xray.cool/#/
2.nuclei
项目地址:https://github.com/projectdiscovery/nuclei
nuclei文档:https://nuclei.projectdiscovery.io/nuclei/get-started/#running-nuclei
3.Goby
官网地址:https://gobies.org/
其他搜集
搜集员工信息,招标信息,github,百度贴吧,新浪微博,手机号,支付宝,论坛,博客,邮箱等
1.邮箱收集:EmailAll
项目地址:https://github.com/Taonn/EmailAll
api.py里配置信息 |
2.公众号/文章搜集:
https://weixin.sogou.com/
3.网盘资源搜集
凌风云:https://www.lingfengyun.com
代理池
ProxyPool
项目地址:https://github.com/jhao104/proxy_pool
3.4.全方位收集
1.灯塔
项目地址:https://github.com/TophantTechnology/ARL
2.水泽
项目地址: https://github.com/0x727/ShuiZe_0x727/
3.Goby
官网地址:https://gobies.org/




