
yolov5入门
课程链接: https://www.bilibili.com/video/BV1G24y1G7qm/?spm_id_from=333.788
1.环境安装
Miniconda:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
conda create -n yolov5 python=3.8 |
一个单独的环境能用pip就用pip,实在有问题用conda
安装Pytorch pytorch.org
NVIDIA控制面板->系统信息->组件可以看到CUDA信息
安装v1.8.2 CUDA11.2(3060)
pip install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111 |
yolov5 https://github.com/ultralytics/yolov5
numpy = 1.20.3 |
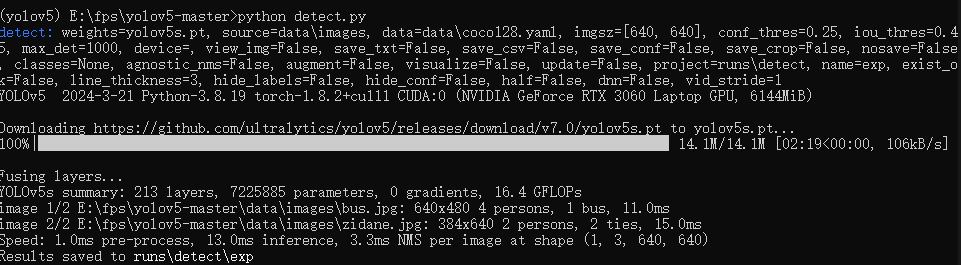
检测安装
python detect.py |
2.Yolov5模型检测
1.关键参数
weights : 指定训练好的模型文件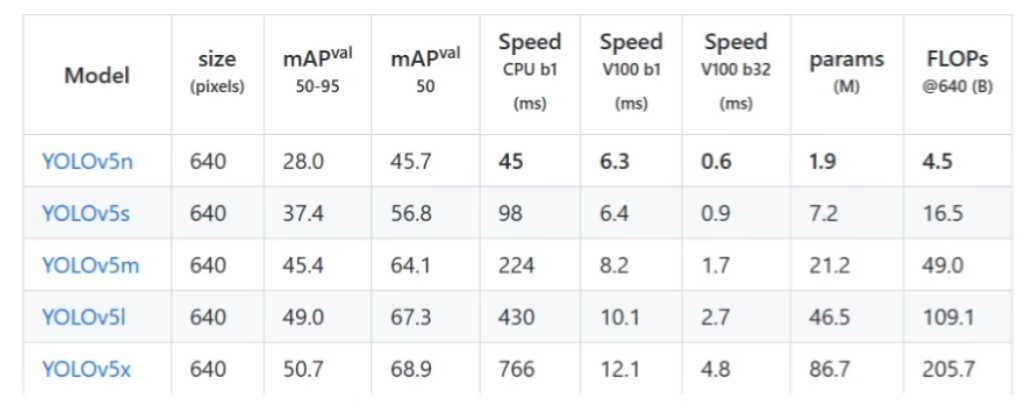
#detect.py |
2.source: 检测的目标,可以是单张图片、文件夹、屏幕或者摄像头等
parser.add_argument("--source", type=str, default=ROOT / "data/images", help="file/dir/URL/glob/screen/0(webcam)") |
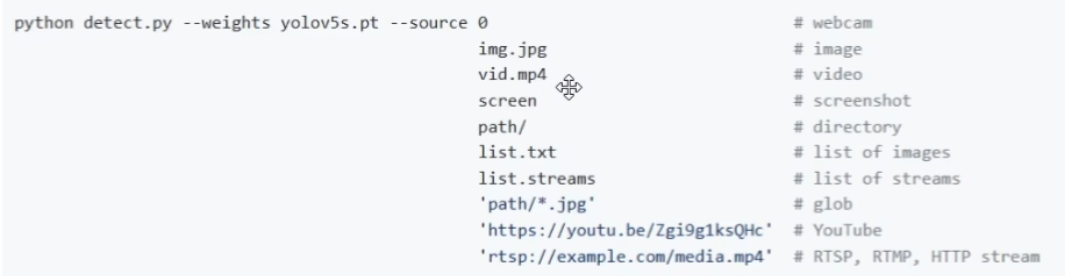
python detect.py --weights .\yolov5s.pt --source data/images/bus.jpg |
 3.conf-thres: 置信度阈值,越低框越多,越高框越少
3.conf-thres: 置信度阈值,越低框越多,越高框越少
parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold") |
python detect.py --weights .\yolov5s.pt |
python detect.py --weights .\yolov5s.pt --conf-thres 0.8 |
 4.iou-thres: IOU阈值,越低框越少,越高框越多
4.iou-thres: IOU阈值,越低框越少,越高框越多
parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU threshold") |
5.--imgsz 输入图像的大小,默认640x640
6.–max-det 一张图片最大的检测数量
7.–device 指定设备
8.–view-img 检测结果弹窗
9.–classes 指定要检测的类别
2.基于torch.hub检测
安装jupyter
pip install jupyter |
import torch |
3.数据集构建
- 准备工作
- 数据收集
- 图片类型数据
- 视频类型数据
- 使用opencv进行视频抽帧
- 数据收集
import cv2 |
标注工具
labelimg
pip install labelimg |
逐个标注
4.模型训练
images: 存放图片
train: 训练集图片
val: 验证集图片
labels: 存放标签
train: 训练集标签文件,要与训练集图片名称一一对应
val: 验证集标签文件,要与验证集图片名称一一对应
images和labels中的train和val要对应
classes.txt文件中的是类名
train.py
weights 预训练的权重文件
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt",help="initial weights path") |
data:数据集描述文件
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path") |
路径指定为data/bvn.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license |
运行
python train.py |
 训练的结果放在runs\\train\\exp文件夹下
其下的best.pt是最好的模型
还有一些其他的结果
events...等文件可以查看训练过程中各项指标的变化
训练的结果放在runs\\train\\exp文件夹下
其下的best.pt是最好的模型
还有一些其他的结果
events...等文件可以查看训练过程中各项指标的变化
tensorboard --logdir runs |
python detect.py --weights runs/train/exp3/weights/best.pt --source yolov5test/test.mp4 --view-img |

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Xrect1fy's blog!
相关推荐




