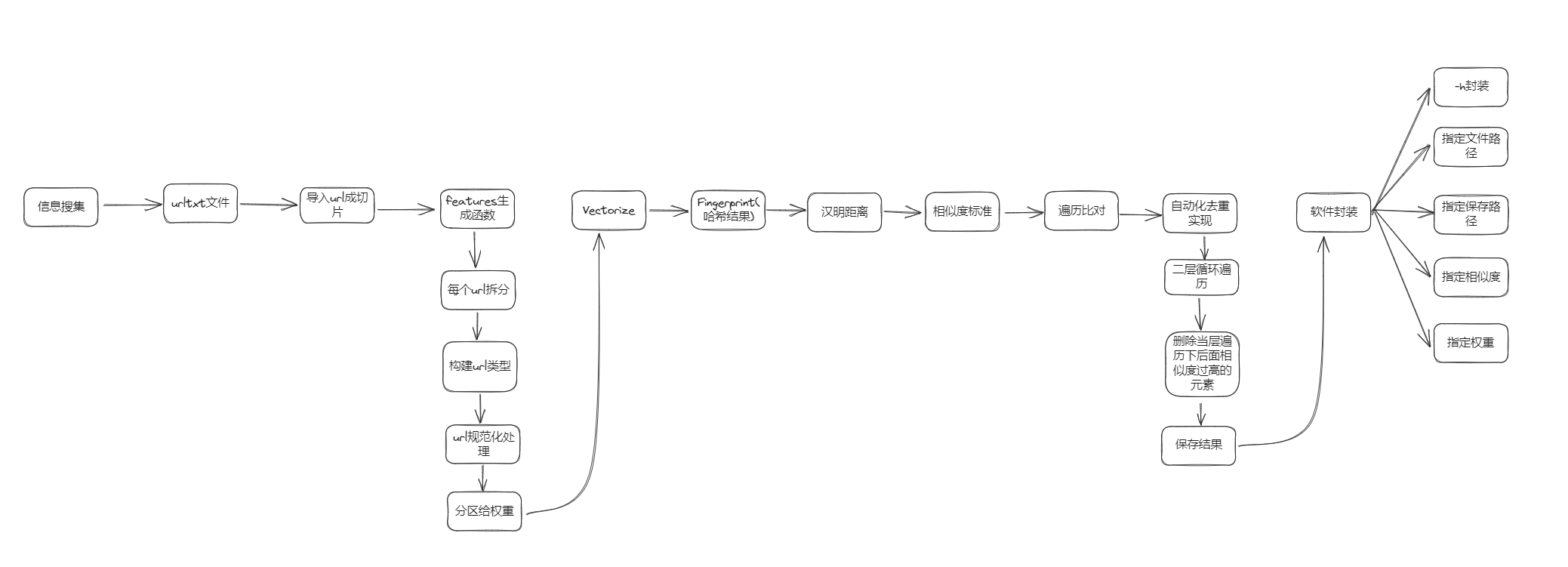
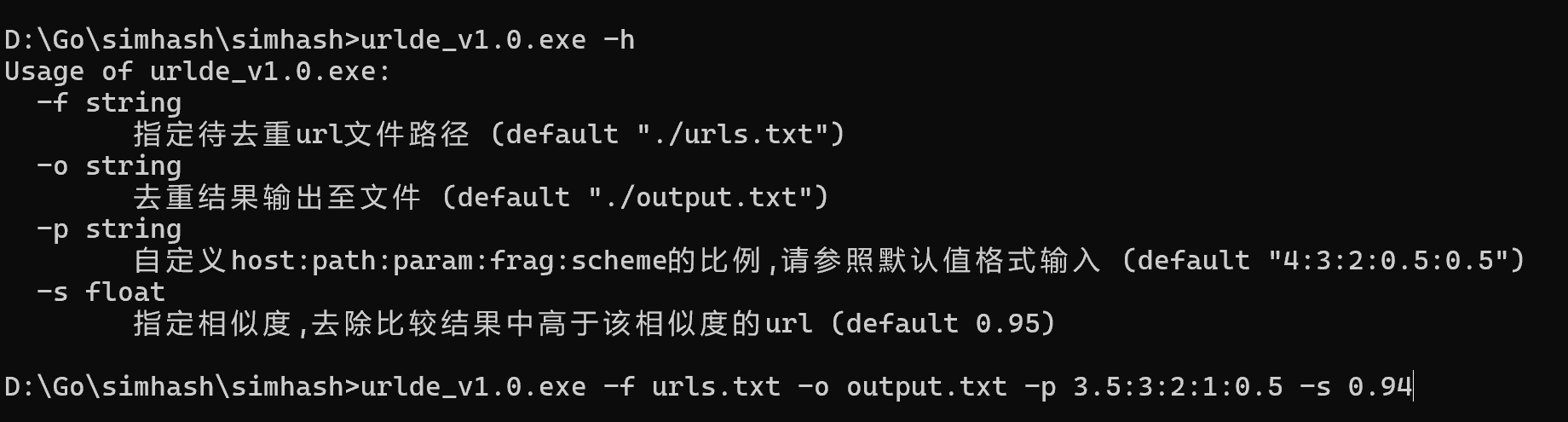
funcmain() { var docs = [][]byte{ []byte("this is a test phrase"), []byte("this is a test phrass"), []byte("foo bar"), }
hashes := make([]uint64, len(docs)) for i, d := range docs { hashes[i] = simhash.Simhash(simhash.NewWordFeatureSet(d)) fmt.Printf("Simhash of %s: %x\\\\n", d, hashes[i]) }
fmt.Printf("Comparison of `%s` and `%s`: %d\\\\n", docs[0], docs[1], simhash.Compare(hashes[0], hashes[1])) fmt.Printf("Comparison of `%s` and `%s`: %d\\\\n", docs[0], docs[2], simhash.Compare(hashes[0], hashes[2])) }
跑出来:
Simhash of this is a test phrase: 8c3a5f7e9ecb3f35 Simhash of this is a test phrass: 8c3a5f7e9ecb3f21 Simhash of foo bar: d8dbe7186bad3db3 Comparison of `this is a test phrase` and `this is a test phrass`: 2 Comparison of `this is a test phrase` and `foo bar`: 29
// Returns a []Feature representing each word in the byte slice func(w *WordFeatureSet) GetFeatures() []Feature { return getFeatures(w.b, boundaries) }
var boundaries = regexp.MustCompile(`[\\\\w']+(?:\\\\://[\\\\w\\\\./]+){0,1}`)
funcgetFeatures(b []byte, r *regexp.Regexp) []Feature { //将原有[]byte分为单词数组 words := r.FindAll(b, -1) //根据单词数量创建空间 features := make([]Feature, len(words)) for i, w := range words { //获取每个单词的feature //feature默认有两个参数(Value,Weight) features[i] = NewFeature(w) } //一个句子返回一个features return features }
funcVectorize(features []Feature) Vector { var v Vector //遍历features里每个单词的feature for _, feature := range features { //获取单个单词的Sum sum := feature.Sum() //获取单个单词的Weight weight := feature.Weight() //64次循环 for i := uint8(0); i < 64; i++ { //依次获取由大到小每一位二进制位 bit := ((sum >> i) & 1) //如果该店bit值为1,则该位权重增加 if bit == 1 { v[i] += weight } else { v[i] -= weight } } } return v }
单独拉出下面的代码测试,发现跑出来是输入数字的二进制编码的每一位
sum := 217 for i := uint8(0); i < 8; i++ { bit := ((sum >> i) & 1) fmt.Printf("%s\n", bit) }
funcCompare(a uint64, b uint64)uint8 { //a与b取异或(按位比较如果相同结果为0,不同结果为1) v := a ^ b // uint8 0-255 var c uint8 //循环条件为 v不等于0 for c = 0; v != 0; c++ { //消除v中最右边的1 v &= v - 1 } //消除完v里所有的1,循环的次数就是c的值 return c }
//避免有控制字符 funcstringContainsCTLByte(s string)bool { for i := 0; i < len(s); i++ { b := s[i] if b < ' ' || b == 0x7f { returntrue } } returnfalse }
//获取schema funcgetScheme(rawURL string) (scheme, path string, err error) { for i := 0; i < len(rawURL); i++ { c := rawURL[i] switch { case'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z': // do nothing case'0' <= c && c <= '9' || c == '+' || c == '-' || c == '.': if i == 0 { return"", rawURL, nil } case c == ':': if i == 0 { return"", "", errors.New("missing protocol scheme") } return rawURL[:i], rawURL[i+1:], nil default: // we have encountered an invalid character, // so there is no valid scheme return "", rawURL, nil } } return"", rawURL, nil }
package simhash import ( "bytes" "golang.org/x/text/unicode/norm" "hash/fnv" "net/url" "regexp" "strings" ) type Vector [64]float64 // Feature consists of a 64-bit hash and a weight type Feature interface { // Sum returns the 64-bit sum of this feature Sum() uint64 // Weight returns the weight of this feature Weight() float64 } type FeatureSet interface { GetFeatures() []Feature }
funcVectorize(features []Feature) Vector { var v Vector //遍历features里每个单词的feature for _, feature := range features { //获取单个单词的Sum sum := feature.Sum() //获取单个单词的Weight weight := feature.Weight() //64次循环 for i := uint8(0); i < 64; i++ { //依次获取由大到小每一位二进制位 bit := ((sum >> i) & 1) //如果该店bit值为1,则该位权重增加 if bit == 1 { v[i] += weight } else { v[i] -= weight } } } return v } funcVectorizeBytes(features [][]byte) Vector { var v Vector h := fnv.New64() for _, feature := range features { h.Reset() h.Write(feature) sum := h.Sum64() for i := uint8(0); i < 64; i++ { bit := ((sum >> i) & 1) if bit == 1 { v[i]++ } else { v[i]-- } } } return v } funcFingerprint(v Vector)uint64 { var f uint64 for i := uint8(0); i < 64; i++ { if v[i] >= 0 { f |= (1 << i) } } return f } type feature struct { sum uint64 weight float64 } func(f feature) Sum() uint64 { return f.sum }
funcCompare(a uint64, b uint64)uint8 { v := a ^ b var c uint8 for c = 0; v != 0; c++ { v &= v - 1 } return c } funcSimhash(fs FeatureSet)uint64 { return Fingerprint(Vectorize(fs.GetFeatures())) }
funcSimhashBytes(b [][]byte)uint64 { return Fingerprint(VectorizeBytes(b)) } type WordFeatureSet struct { b []byte } funcNewWordFeatureSet(b []byte) *WordFeatureSet { fs := &WordFeatureSet{b} fs.normalize() return fs } func(w *WordFeatureSet) normalize() { w.b = bytes.ToLower(w.b) } var boundaries = regexp.MustCompile(`[\w']+(?:\://[\w\./]+){0,1}`) var unicodeBoundaries = regexp.MustCompile(`[\pL-_']+`)
func(w *WordFeatureSet) GetFeatures() []Feature { return getFeatures(w.b, boundaries) } type UnicodeWordFeatureSet struct { b []byte f norm.Form } funcNewUnicodeWordFeatureSet(b []byte, f norm.Form) *UnicodeWordFeatureSet { fs := &UnicodeWordFeatureSet{b, f} fs.normalize() return fs } func(w *UnicodeWordFeatureSet) normalize() { b := bytes.ToLower(w.f.Append(nil, w.b...)) w.b = b }
funcgetFeatures(b []byte, r *regexp.Regexp) []Feature { //将原有[]byte分为单词数组 words := r.FindAll(b, -1) //根据单词数量创建空间 features := make([]Feature, len(words)) for i, w := range words { //获取每个单词的feature //feature默认有两个参数(Value,Weight) features[i] = NewFeature(w) } //一个句子返回一个features return features }
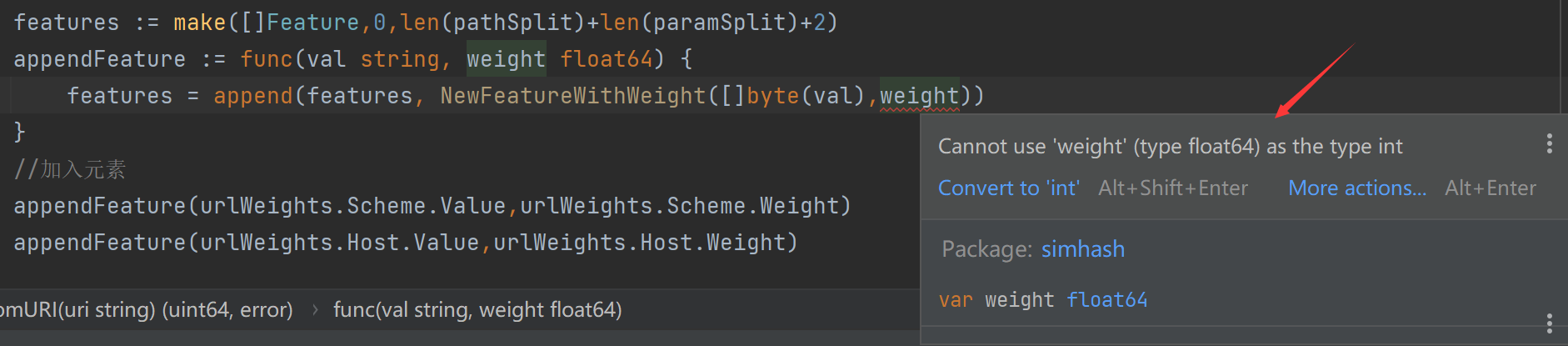
funcShingle(w int, b [][]byte) [][]byte { if w < 1 { // TODO: use error here instead of panic? panic("simhash.Shingle(): k must be a positive integer") } if w == 1 { return b } if w > len(b) { w = len(b) } count := len(b) - w + 1 shingles := make([][]byte, count) for i := 0; i < count; i++ { shingles[i] = bytes.Join(b[i:i+w], []byte(" ")) } return shingles } type pw struct{ Value string Weight float64 } type urlt struct { Host pw Path pw RawQuery pw Fragment pw Scheme pw } //func getFeaturesFromURI(uri string) ([]Feature, error) { funcGetFeaturesFromURI(uri string) []Feature { parse,err := url.Parse(uri) if err!= nil{ returnnil } urlWeights := Setutval_wei(parse.Host,parse.Path,parse.RawQuery,parse.Fragment,parse.Scheme) //处理url urlWeights.Path.Value = strings.ReplaceAll(urlWeights.Path.Value,"//","/") _,urlWeights.Path.Value,_ = strings.Cut(urlWeights.Path.Value,"/") urlWeights.RawQuery.Value = strings.ReplaceAll(urlWeights.RawQuery.Value,"&&","&") //路径分割、参数分割 pathSplit := strings.Split(urlWeights.Path.Value,"/") paramSplit := strings.Split(urlWeights.RawQuery.Value,"&") //两块小N权重计算 pathWeight := calculateWeight(urlWeights.Path.Weight,len(pathSplit)) paramWeight := calculateWeight(urlWeights.RawQuery.Weight,len(paramSplit)) //返回结果初始化 //文章方法默认没有加上Fragment features := make([]Feature,0,len(pathSplit)+len(paramSplit)+2) appendFeature := func(val string, weight float64) { features = append(features, NewFeatureWithWeight([]byte(val),weight)) } //加入元素 appendFeature(urlWeights.Scheme.Value,urlWeights.Scheme.Weight) appendFeature(urlWeights.Host.Value,urlWeights.Host.Weight) //2块小N for _,value := range pathSplit { appendFeature(value,pathWeight) } for _,value := range paramSplit { appendFeature(value,paramWeight) } return features } funcSetutval_wei(val1, val2, val3, val4, val5 string) urlt { return urlt{ Host: pw{ Value: val1, Weight:4, }, Path: pw{ Value: val2, Weight:3, }, RawQuery: pw{ Value: val3, Weight:2, }, Fragment: pw{ Value: val4, Weight: 0.5, }, Scheme: pw{ Value: val5, Weight: 0.5, }, } } //算权重 funccalculateWeight(totalWeight float64, partsCount int)float64 { if partsCount > 0 { return totalWeight / float64(partsCount) } return totalWeight }
main.go
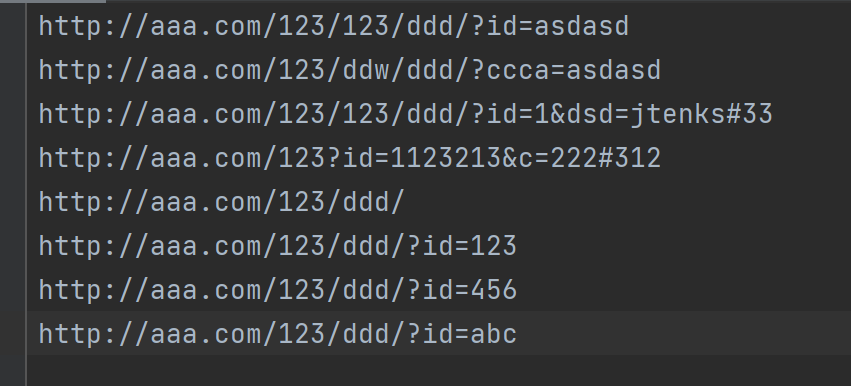
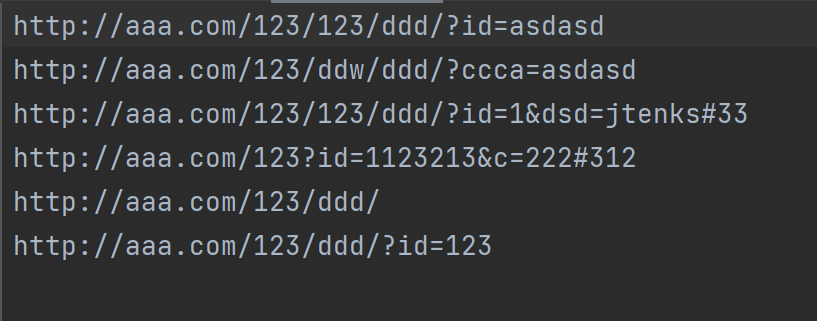
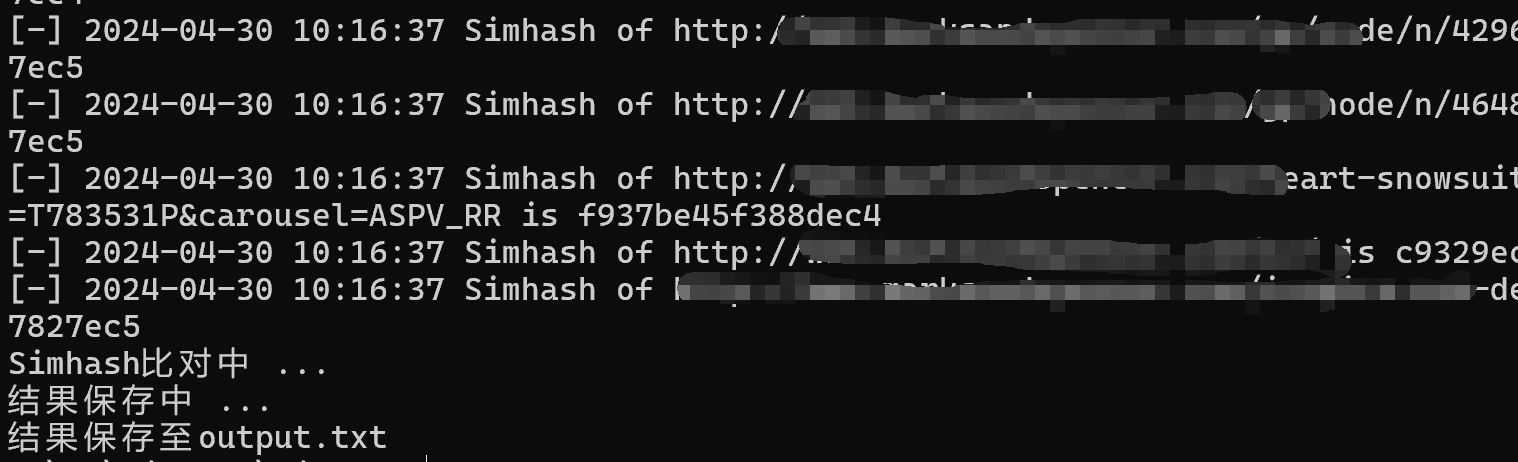
package main import ( "bufio" "fmt""github.com/mfonda/simhash""os") funcmain() { //文件路径 filePath := "test.txt" //文件里读出url urls, err := inputFile(filePath) if err != nil { fmt.Println("Error:", err) return } //遍历url hashes := make([]uint64, len(urls)) fmt.Printf("Result of Simhash :\n") for i, single_url := range urls { hashes[i] = simhash.Fingerprint(simhash.Vectorize(simhash.GetFeaturesFromURI(string(single_url)))) fmt.Printf("Simhash of %s is %x\n", single_url, hashes[i]) } fmt.Printf("Result of Comparision :\n") for i, _ := range urls { for j := i + 1; j < len(urls); j++ { fmt.Printf("Comparison of `%s` and `%s`: %.5f%% \n", urls[i], urls[j], similarity(hashes[i], hashes[j])) } } fmt.Printf("Comparison of `%s` and `%s`: %.5f%% \n", urls[0], urls[1], similarity(hashes[0], hashes[1])) } funcinputFile(filePath string) ([][]byte, error) { // 打开文本文件 file, err := os.Open(filePath) if err != nil { returnnil, fmt.Errorf("error opening file: %v", err) } defer file.Close() var urls [][]byte // 逐行读取文件内容 scanner := bufio.NewScanner(file) for scanner.Scan() { // 获取每行的 URL url := scanner.Text() // 将URL转换为所需的格式 formattedURL := []byte(url) // 添加到切片中 urls = append(urls, formattedURL) } // 检查扫描过程中是否有错误 if err := scanner.Err(); err != nil { returnnil, fmt.Errorf("error scanning file: %v", err) } return urls, nil } // 百分比计算 funcsimilarity(a uint64, b uint64)float64 { percent := simhash.Compare(a, b) return100 - (float64(percent)/64.0)*100 }

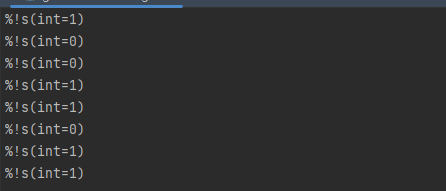 原代码右移左侧补0,上述操作可以求得由大到小每一feature的sum的二进制位。如果有feature的二进制位为1则v进1,否则v减1。
原代码右移左侧补0,上述操作可以求得由大到小每一feature的sum的二进制位。如果有feature的二进制位为1则v进1,否则v减1。