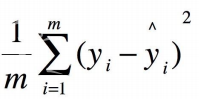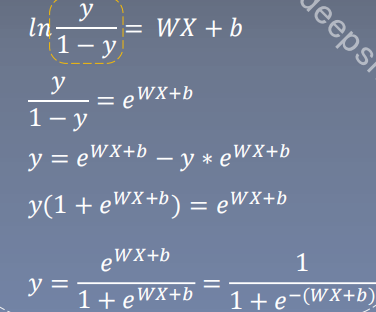深度学习基础 | 字数总计: 5.1k | 阅读时长: 24分钟 | 阅读量:
学习视频:https://www.bilibili.com/video/BV1zS4y1n7Eq/?spm_id_from=333.1007.top_right_bar_window_history.content.click
1.Pytorch基础概念 1.Pytorch安装 运行
查看cuda版本,去官网下载对应版本cuda
CUDNN安装:https://developer.nvidia.com/cudnn https://pytorch.org/ https://download.pytorch.org/whl/torch_stable.html
https://download.pytorch.org/whl/cu116/torchvision-0.14.0%2Bcu116-cp38-cp38-win_amd64.whl https://download.pytorch.org/whl/cu116/torch-1.12.0%2Bcu116-cp38-cp38-win_amd64.whl
下载完成后放到同一个文件夹中
conda
//conda创建虚拟环境 conda create -n [环境名] python=3.8 //激活虚拟环境 conda activate [环境名] //进入存放torch和torchvisionwhl文件的目录中 cd [文件目录路径] //安装torch pip install "torch文件名.whl" //安装torchvision pip install "torchvision文件名.whl"
pycharm设置
设置完成后运行
import torch print ("Hello torch {}" .format (torch.__version__))print (torch.cuda.is_available())
成功输出版本
Hello torch 1.13.0+cpu True
2.Tensor张量 1.张量概念 张量是一个多维数组,它是标量、向量、矩阵的高维拓展。
2.创建张量 1.直接创建
torch.tensor()torch.tensor( data, dtype=None , device=None , requires_grad=False , pin_memory=False ) data:数据,可以是list ,numpy dtype:数据类型 device:所在设备 requires_grad: 是否需要梯度 pin_memory: 是否存于锁页内存 import torchimport numpy as npflag = True if flag: arr = np.ones((3 , 3 )) print ("ndarray数据类型" , arr.dtype) t = torch.tensor(arr, device="cuda" ) print (t)
torch.from_numpy(ndarray)
2.依据数值创建
torch.zeros()torch.zeros(*size, out=None , dtype=None , layout=torch.strided, device=None , requires_grad=False ) size:张量的形状 out:输出的张量 layout:内存中布局形式,有strided,sparse_coo等 device:所在设备 requires_grad:是否需要梯度 out_t = torch.tensor([1 ]) t = torch.zeros((3 , 3 ), out=out_t) print (t, "\n" , out_t)print (id (t), id (out_t), id (t) == id (out_t))两者同一内存空间
torch.zeros_like()torch.zeros_like(input , dtype=None , layout=None , device=None , requires_grad=False ) input :创建与input 同形状的全0 张量dtype:数据类型 layout:内存中的布局形式
torch.ones() torch.ones_like()同理
torch.full()torch.full(size, fill_value, dtype=None , out=None , layout=torch.strided, device=None , requires_grad=False ) size:张量的形状如(3 ,3 ) fill_value:张量的值 t = torch.full((3 , 3 ), 10 ) print (t)
torch.arange()torch.arange(start=0 , end, step=1 , out=None , dtype=None , layout=torch.strided, device=None , requires_grad=False ) start:数列起始值 end:数列"结束值" step:数列公差,默认为1 t = torch.arange(2 , 10 , 2 ) print (t)
torch.linspace()torch.linspace(start, end, steps=100 , out=None , dtype=None , layout=torch.strided, device=None , requires_grad=False ) start:数列起始值 end:数列结束值 steps:数列长度 t = torch.linspace(2 , 10 , 6 ) print (t)
torch.logspace()torch.logspace(start, end, steps=100 , base=10.0 , out=None , dtype=None , layout=torch.strided, device=None , requires_grad=False ) start:数列起始值 end:数列结束值 steps:数列长度 base:对数函数的底,默认为10
torch.eye()torch.eye(n, m=None , out=None , dtype=None , layout=torch.strided, device=None , requires_grad=False ) n:矩阵行数,默认只设置行数 m:矩阵列数
3.依概率分布创建张量
torch.nomal()
torch.normal(mean, std, out=None ) mean:均值 std:标推差 两者均可为向量或标量 flag = True if flag: t_normal = torch.normal(0. ,1. ,size=(4 ,)) print (t_normal) mean = torch.arange(1 ,5 ,dtype=torch.float ) std = 1 t_normal = torch.normal(mean,std) print ("mean:{}\nstd:{}" .format (mean,std)) print (t_normal)
torch.randn()标准正态分布
torch.randn_like()生成标准正态分布,设置size即可
torch.rand()生成均匀分布
torch.rand_like() 在区间[0,1)上,生成均匀分布
torch.randint()
torch.randint_like()功能:区间[low,high)生成整数均匀分布,size:张量形状
torch.randperm()
torch.randperm(n, out=None, dtype=torch.int64, layout=torch.strided, device=None, requires_grad=False )
torch.bernoulli
torch.bernoulli(input, *, generator=None, out=None )
3.张量操作 1.拼接与切分 1.torch.cat()将张量按维度dim进行拼接
torch.cat(tensors, dim=0 , out=None ) t = torch.ones((2 , 3 )) t_0 = torch.cat([t, t], dim=0 ) t_1 = torch.cat([t, t], dim=1 ) print ("t_0:{} shape:{}\nt_1:{} shape:{}" .format (t_0, t_0.shape, t_1, t_1.shape))t_0:tensor([[1. , 1. , 1. ], [1. , 1. , 1. ], [1. , 1. , 1. ], [1. , 1. , 1. ]]) shape:torch.Size([4 , 3 ]) t_1:tensor([[1. , 1. , 1. , 1. , 1. , 1. ], [1. , 1. , 1. , 1. , 1. , 1. ]]) shape:torch.Size([2 , 6 ])
2.torch.stack() 在新创建的维度dim上进行拼接
torch.stack(tensors, dim=0 , out=None ) t = torch.ones((2 , 3 )) t_test = torch.stack([t, t], dim=2 ) print ("t_test:{} shape:{}" .format (t_test, t_test.shape))t_test:tensor([[[1. , 1. ], [1. , 1. ], [1. , 1. ]], [[1. , 1. ], [1. , 1. ], [1. , 1. ]]]) shape:torch.Size([2 , 3 , 2 ]) t = torch.ones((2 , 3 )) t_test = torch.stack([t, t, t], dim=0 ) print ("t_test:{} shape:{}" .format (t_test, t_test.shape))t_test:tensor([[[1. , 1. , 1. ], [1. , 1. , 1. ]], [[1. , 1. , 1. ], [1. , 1. , 1. ]], [[1. , 1. , 1. ], [1. , 1. , 1. ]]]) shape:torch.Size([3 , 2 , 3 ])
!cat不会扩充张量维度,但是stack会扩充张量维度
torch.chunk(input , chunks, dim=0 ) a = torch.ones((2 , 5 )) list_of_tensors = torch.chunk(a, dim=1 , chunks=2 ) for idx, t in enumerate (list_of_tensors): print ("第{}个张量:{},shape is{}" .format (idx + 1 , t, t.shape)) 第1 个张量:tensor([[1. , 1. , 1. ], [1. , 1. , 1. ]]),shape istorch.Size([2 , 3 ]) 第2 个张量:tensor([[1. , 1. ], [1. , 1. ]]),shape istorch.Size([2 , 2 ])
4.torch.split()
torch.split(tensor, split_size_or_sections, dim=0 ) t = torch.ones((2 , 5 )) list_of_tensors = torch.split(t, 2 , dim=1 ) for idx, t in enumerate (list_of_tensors): print ("第{}个张量:{}, shape is {}" .format (idx + 1 , t, t.shape)) 第1 个张量:tensor([[1. , 1. ], [1. , 1. ]]), shape is torch.Size([2 , 2 ]) 第2 个张量:tensor([[1. , 1. ], [1. , 1. ]]), shape is torch.Size([2 , 2 ]) 第3 个张量:tensor([[1. ], [1. ]]), shape is torch.Size([2 , 1 ]) t = torch.ones((2 , 5 )) list_of_tensors = torch.split(t, [2 , 1 , 2 ], dim=1 ) for idx, t in enumerate (list_of_tensors): print ("第{}个张量:{}, shape is {}" .format (idx + 1 , t, t.shape)) 第1 个张量:tensor([[1. , 1. ], [1. , 1. ]]), shape is torch.Size([2 , 2 ]) 第2 个张量:tensor([[1. ], [1. ]]), shape is torch.Size([2 , 1 ]) 第3 个张量:tensor([[1. , 1. ], [1. , 1. ]]), shape is torch.Size([2 , 2 ]) !注意:list 切分时,list 里数据求和后等于dim对应的长度
2.张量索引 1.torch.index_select()
torch.index select(input , dim, index, out=None ) t = torch.randint(0 , 9 , size=(3 , 3 )) idx = torch.tensor([0 , 2 ], dtype=torch.long) t_select = torch.index_select(t, dim=0 , index=idx) print ("t:\n{}\nt_select:\n{}" .format (t, t_select))t: tensor([[4 , 5 , 0 ], [5 , 7 , 1 ], [2 , 5 , 8 ]]) t_select: tensor([[4 , 5 , 0 ], [2 , 5 , 8 ]])
2.torch.masked_select()
torch.masked_select(input , mask, out=None ) t = torch.randint(0 , 9 , size=(3 , 3 )) mask = t.le(5 ) t_select = torch.masked_select(t, mask) print ("t:\n{}\nmask:\n{}\nt_select:\n{} " .format (t, mask, t_select))t: tensor([[4 , 5 , 0 ], [5 , 7 , 1 ], [2 , 5 , 8 ]]) mask: tensor([[ True , True , True ], [ True , False , True ], [ True , True , False ]]) t_select: tensor([4 , 5 , 0 , 5 , 1 , 2 , 5 ])
3.张量变换 1.torch. reshape( )
torch.reshape(input , shape ) t = torch.randperm(8 ) t_reshape = torch.reshape(t, (-1 , 2 , 2 )) print ("t:{}\nt_reshape:\n{}" .format (t, t_reshape))t[0 ] = 1024 print ("t:{}\nt_reshape:\n{}" .format (t, t_reshape))print ("t.data 内存地址:{}" .format (id (t.data)))print ("t_reshape.data 内存地址:{}" .format (id (t_reshape.data)))t:tensor([5 , 4 , 2 , 6 , 7 , 3 , 1 , 0 ]) t_reshape: tensor([[[5 , 4 ], [2 , 6 ]], [[7 , 3 ], [1 , 0 ]]]) t:tensor([1024 , 4 , 2 , 6 , 7 , 3 , 1 , 0 ]) t_reshape: tensor([[[1024 , 4 ], [ 2 , 6 ]], [[ 7 , 3 ], [ 1 , 0 ]]]) t.data 内存地址:1921793389440 t_reshape.data 内存地址:1921722186048
2.torch.transpose()
torch.transpose(input , dim0, dim1 ) t = torch.rand((2 , 3 , 4 )) t_transpose = torch.transpose(t, dim0=1 , dim1=2 ) print ("t shape:{}\nt_transpose shape: {}" .format (t.shape, t_transpose.shape))t shape:torch.Size([2 , 3 , 4 ]) t_transpose shape: torch.Size([2 , 4 , 3 ]) torch.t(input )
4.torch.squeeze()
torch.squeeze(input , dim=None , out=None ) t = torch.rand((1 , 2 , 3 , 1 )) t_sq = torch.squeeze(t) t_0 = torch.squeeze(t, dim=0 ) t_1 = torch.squeeze(t, dim=1 ) print (t.shape)print (t_sq.shape)print (t_0.shape)print (t_1.shape)torch.Size([1 , 2 , 3 , 1 ]) torch.Size([2 , 3 ]) torch.Size([2 , 3 , 1 ]) torch.Size([1 , 2 , 3 , 1 ])
3.5 torch.unsqueeze()
torch.usqueeze(input , dim, out=None )
4.张量数学运算 torch.add() torch.addcdiv() torch.addcmul() torch.sub() torch.div() torch.mul() torch.log(input ,out=None ) torch.log10(input ,out=None ) torch.log2(input ,out=None ) torch.exp(input ,out=None ) torch.pow () torch.abs (input ,out=None ) torch.acos(input ,out=None ) torch.cosh(input ,out=None ) torch.cos(input ,out=None ) torch.asin(input ,out=None ) torch.atan(input ,out=None ) torch.atan2(input ,other,out=None )
torch.add()
torch.add(input , alpha=1 , other, out=None ) t_0 = torch.randn((3 , 3 )) t_1 = torch.ones_like(t_0) t_add = torch.add(t_0, 10 , t_1) print ("t_0:\n{}\nt_1:\n{}\nt_add_10:\n{}" .format (t_0, t_1, t_add))t_0: tensor([[ 0.6614 , 0.2669 , 0.0617 ], [ 0.6213 , -0.4519 , -0.1661 ], [-1.5228 , 0.3817 , -1.0276 ]]) t_1: tensor([[1. , 1. , 1. ], [1. , 1. , 1. ], [1. , 1. , 1. ]]) t_add_10: tensor([[10.6614 , 10.2669 , 10.0617 ], [10.6213 , 9.5481 , 9.8339 ], [ 8.4772 , 10.3817 , 8.9724 ]])
补
5.线性回归 1.线性回归是分析一个变量与另外一(多)个变量之间关系的方法
2.求解步骤
b.选择损失函数
c.求解梯度并更新w,b
3.线性回归模型的实现
""" @file name : lesson-03-Linear-Regression.py @author : tingsongyu @date : 2018-10-15 @brief : 一元线性回归模型 """ import torchimport matplotlib.pyplot as plttorch.manual_seed(10 ) lr = 0.05 x = torch.rand(20 , 1 ) * 10 y = 2 *x + (5 + torch.randn(20 , 1 )) w = torch.randn((1 ), requires_grad=True ) b = torch.zeros((1 ), requires_grad=True ) for iteration in range (1000 ): wx = torch.mul(w, x) y_pred = torch.add(wx, b) loss = (0.5 * (y - y_pred) ** 2 ).mean() loss.backward() b.data.sub_(lr * b.grad) w.data.sub_(lr * w.grad) w.grad.zero_() b.grad.zero_() if iteration % 20 == 0 : plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-' , lw=5 ) plt.text(2 , 20 , 'Loss=%.4f' % loss.data.numpy(), fontdict={'size' : 20 , 'color' : 'red' }) plt.xlim(1.5 , 10 ) plt.ylim(8 , 28 ) plt.title("Iteration: {}\nw: {} b: {}" .format (iteration, w.data.numpy(), b.data.numpy())) plt.pause(0.5 ) if loss.data.numpy() < 1 : break
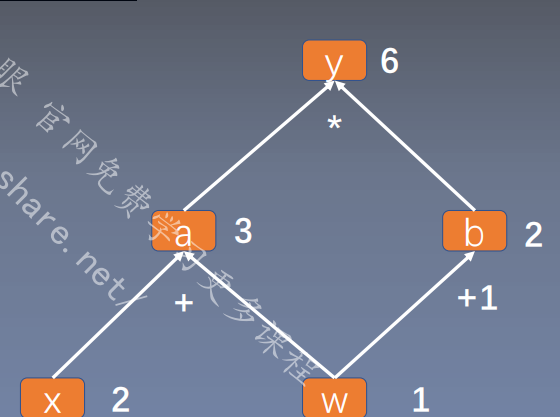
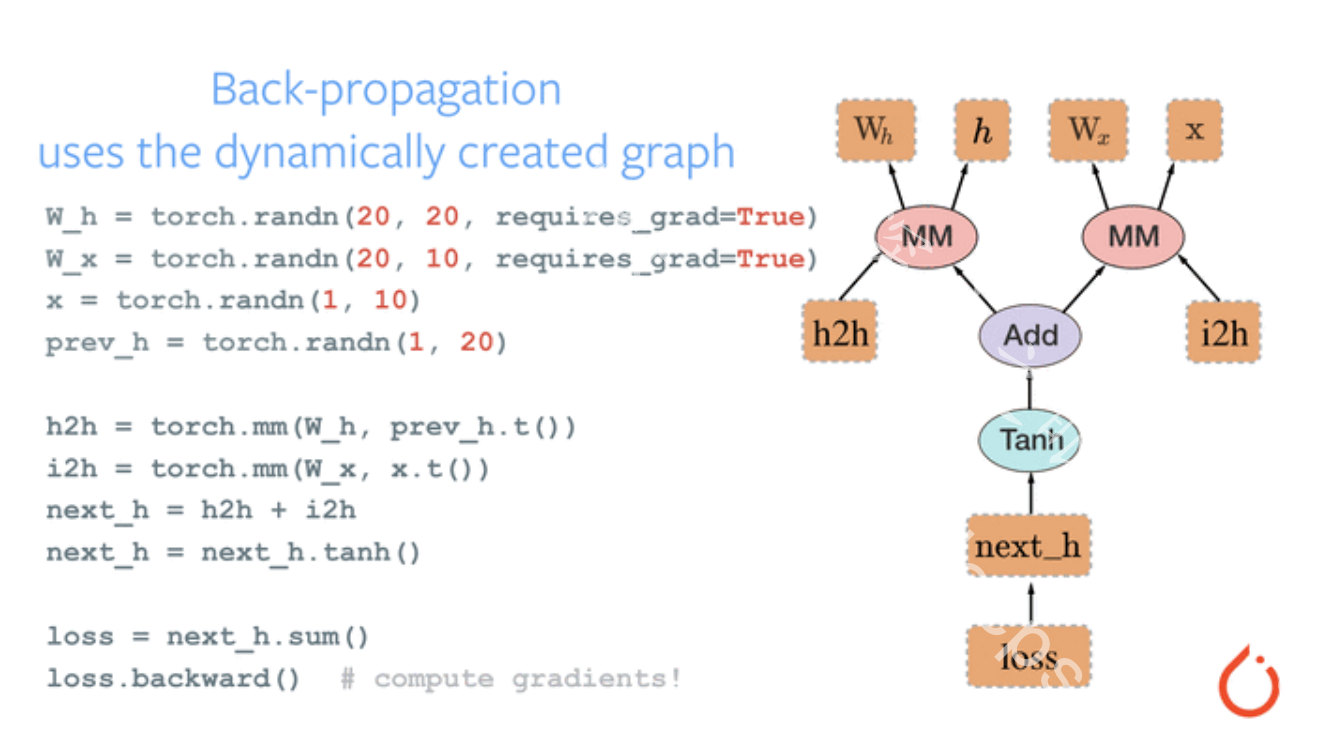
3.计算图与动态图机制 1.计算图 1.计算图是用来描述运算的有向无环图
结点表示数据,如向量,矩阵,张量
用计算图表示:y = (x+ w) * (w+1)
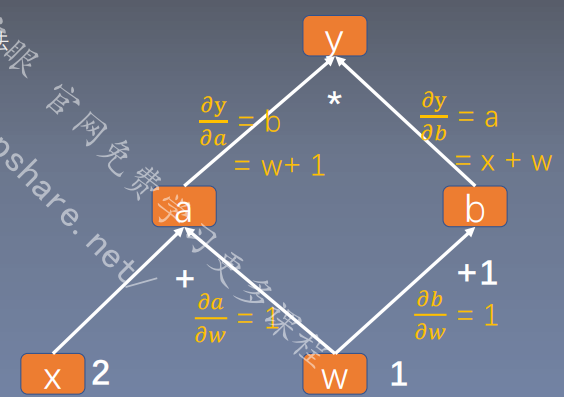
2.计算图与梯度求导
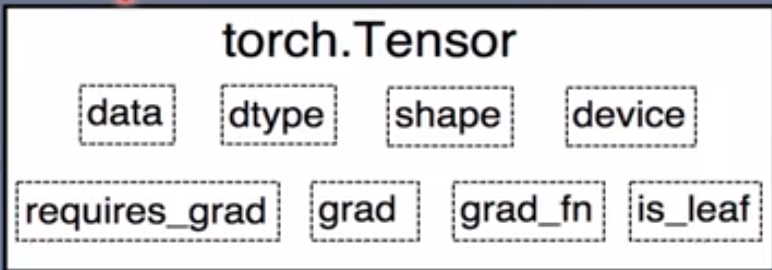
""" @file name : lesson-04-Computational-Graph.py @author : tingsongyu @date : 2018-08-28 @brief : 计算图示例 """ import torchw = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) a = torch.add(w, x) b = torch.add(w, 1 ) y = torch.mul(a, b) print ("is_leaf:\n" , w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)y.backward() print (w.grad)print ("gradient:\n" , w.grad, x.grad, a.grad, b.grad, y.grad)print ("grad_fn:\n" , w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)tensor([5. ]) is_leaf: True True False False False gradient: tensor([5. ]) tensor([2. ]) None None None grad_fn: None None <AddBackward0 object at 0x00000190721A40D0 > <AddBackward0 object at 0x00000190721DAD30 > <MulBackward0 object at 0x0000019073FD35B0 >
3.叶子结点:用户创建的结点称为叶子结点,如X与W
a = torch.add(w,x) a.retain_grad()
4.grad_fn记录创建该张量时所用的方法
2.动态图 根据计算图搭建方式,可将计算图分为动态图和静态图
静态图:先搭建图,后运算 高效不灵活
4.autograd与逻辑回归 1.autograd 1.backward 1.torch.autograd.backward
torch.autograd.backward(tensors, grad_tensors=None , retain_graph=None , create_graph=False )
2.调用.backward方法就是调用torch.autograd.backward(调试可见)
要两次反向传播第一次需要保存计算图
w = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) a = torch.add(w, x) b = torch.add(w, 1 ) y = torch.mul(a, b) y.backward(retain_graph=True ) y.backward()
3.gradient设置多梯度权重
w = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) a = torch.add(w, x) b = torch.add(w, 1 ) y0 = torch.mul(a, b) y1 = torch.add(a, b) loss = torch.cat([y0, y1], dim=0 ) grad_tensors = torch.tensor([1.0 , 2.0 ]) loss.backward( gradient=grad_tensors ) print (w.grad)
2.grad 1.torch.autograd.grad
torch.autograd.grad(outputs, inputs, grad_outputs=None , retain_graph=None , create_graph=False ) x = torch.tensor([3.0 ], requires_grad=True ) y = torch.pow (x, 2 ) grad_1 = torch.autograd.grad( y, x, create_graph=True ) print (grad_1)grad_2 = torch.autograd.grad(grad_1[0 ], x) print (grad_2)(tensor([6. ], grad_fn=<MulBackward0>),) (tensor([2. ]),)
2.注意:
w = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) for i in range (4 ): a = torch.add(w, x) b = torch.add(w, 1 ) y = torch.mul(a, b) y.backward() print (w.grad) tensor([5. ]) tensor([10. ]) tensor([15. ]) tensor([20. ])
解出梯度后需要手动清零
w = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) for i in range (4 ): a = torch.add(w, x) b = torch.add(w, 1 ) y = torch.mul(a, b) y.backward() print (w.grad) w.grad.zero_() tensor([5. ]) tensor([5. ]) tensor([5. ]) tensor([5. ])
b.依赖于叶子结点的结点,requires_grad默认为True
w = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) a = torch.add(w, x) b = torch.add(w, 1 ) y = torch.mul(a, b) print (a.requires_grad, b.requires_grad, y.requires_grad)True True True
c.叶子节点不可执行in-place(原地操作)
w = torch.tensor([1.0 ], requires_grad=True ) x = torch.tensor([2.0 ], requires_grad=True ) a = torch.add(w, x) b = torch.add(w, 1 ) y = torch.mul(a, b) w.add_(1 ) y.backward() Traceback (most recent call last): File "main.py" , line 127 , in <module> w.add_(1 ) RuntimeError: a leaf Variable that requires grad is being used in an in -place operation.
in-place操作学习
a = torch.ones((1 ,)) print (id (a), a)a += torch.ones((1 ,)) print (id (a), a)2006144672256 tensor([1. ])2006144672256 tensor([2. ])
原地操作要求前后操作变量内存地址不变
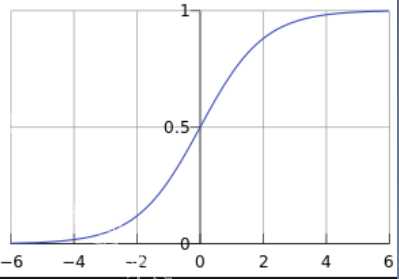
2.逻辑回归 1.逻辑回归是线性二分类模型
""" # @file name : lesson-05-Logsitic-Regression.py # @author : tingsongyu # @date : 2019-09-03 10:08:00 # @brief : 逻辑回归模型训练 """ import torchimport torch.nn as nnimport matplotlib.pyplot as pltimport numpy as nptorch.manual_seed(10 ) sample_nums = 100 mean_value = 1.7 bias = 1 n_data = torch.ones(sample_nums, 2 ) x0 = torch.normal(mean_value * n_data, 1 ) + bias y0 = torch.zeros(sample_nums) x1 = torch.normal(-mean_value * n_data, 1 ) + bias y1 = torch.ones(sample_nums) train_x = torch.cat((x0, x1), 0 ) train_y = torch.cat((y0, y1), 0 ) class LR (nn.Module): def __init__ (self ): super (LR, self).__init__() self.features = nn.Linear(2 , 1 ) self.sigmoid = nn.Sigmoid() def forward (self, x ): x = self.features(x) x = self.sigmoid(x) return x lr_net = LR() loss_fn = nn.BCELoss() lr = 0.01 optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9 ) for iteration in range (1000 ): y_pred = lr_net(train_x) loss = loss_fn(y_pred.squeeze(), train_y) loss.backward() optimizer.step() optimizer.zero_grad() if iteration % 20 == 0 : mask = y_pred.ge(0.5 ).float ().squeeze() correct = (mask == train_y).sum () acc = correct.item() / train_y.size(0 ) plt.scatter(x0.data.numpy()[:, 0 ], x0.data.numpy()[:, 1 ], c='r' , label='class 0' ) plt.scatter(x1.data.numpy()[:, 0 ], x1.data.numpy()[:, 1 ], c='b' , label='class 1' ) w0, w1 = lr_net.features.weight[0 ] w0, w1 = float (w0.item()), float (w1.item()) plot_b = float (lr_net.features.bias[0 ].item()) plot_x = np.arange(-6 , 6 , 0.1 ) plot_y = (-w0 * plot_x - plot_b) / w1 plt.xlim(-5 , 7 ) plt.ylim(-7 , 7 ) plt.plot(plot_x, plot_y) plt.text(-5 , 5 , 'Loss=%.4f' % loss.data.numpy(), fontdict={'size' : 20 , 'color' : 'red' }) plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}" .format (iteration, w0, w1, plot_b, acc)) plt.legend() plt.show() plt.pause(0.5 ) if acc > 0.99 : break
2.Pytorch数据处理 3.Pytorch模型搭建 4.Pytorch损失优化 5.Pytorch训练过程 6.Pytorch的正则化 7.Pytorch的训练技巧 8.Pytorch深度体验